Рядки в мові JavaScript

Лекція
Тема. Рядки в мові програмування JavaScript.
План
- Робота з рядками.
- Методи та функції роботи з рядками
Список рекомендованих джерел
- Босько В.В., Константинова Л.В., Марченко К.М., Улічев О.С. Web-програмування. Частина 1 (frontend) : навч. посіб. Кропивницький: ЦНТУ, 2022. 208 с.
- Двірничук К.В., Вацек Д.О. Д. Веб-програмування та веб-дизайн : навч. посіб. Чернівці : Чернівец. нац. ун-т ім. Ю. Федьковича, 2022. 472 с.
- Мова програмування JavaScript. URL: https://uk.javascript.info/js/
- Цеслів О.В. Основи програмування та веб-дизайн: Навч. посіб. Київ, 2020. 149с.
Зміст лекції
У JavaScript текстові дані зберігаються у вигляді рядків. Не існує окремого типу для одного символу.
Внутрішній формат для рядків завжди UTF-16, він не привʼязаний до кодування сторінки.
1. Робота з рядками. Лапки
Згадаймо види лапок.
Рядки можуть бути включені в одинарні лапки, подвійні лапки або зворотні знаки:
let single = 'одинарні-лапки';
let double = "подвійні-лапки";
let backticks = `зворотні-лапки`;
Одинарні та подвійні лапки по суті однакові. Однак зворотні лапки дозволяють нам вставляти будь-який вираз у рядок, загортаючи його у ${…}:
function sum(a, b) {
return a + b;
}
alert(`1 + 2 = ${sum(1, 2)}.`); // 1 + 2 = 3.
Ще однією перевагою використання зворотних лапок є те, що вони дозволяють рядку охоплювати кілька ліній:
let guestList = `Гості:
* Іван
* Петро
* Марія
`;
alert(guestList); // список гостей в кілька рядків
Виглядає природно, правда? Але одинарні або подвійні лапки так не працюють.
Якщо ми спробуємо їх використати в кілька рядків, буде помилка:
let guestList = "Гості: // Помилка: Unexpected token ILLEGAL
* Іван";
Одинарні та подвійні лапки беруть свій початок з давніх часів створення мови, коли не було потреби у багатолінійних рядках. Зворотні лапки зʼявилися набагато пізніше і тому є більш універсальними.
Зворотні лапки також дозволяють нам задати “шаблонну функцію” перед першими зворотніми лапками. Синтаксис такий: func`string`. Функція func викликається автоматично, отримує рядок і вбудовані в неї вирази і може їх обробити. Це називається “теговим шаблоном”, це рідко використовується на практиці, але ви можете прочитати детальніше про це на MDN: Template literals.
Ще можна створити багатолінійні рядки з одинарними та подвійними лапками за допомогою так званого “символу нового рядка”, записаного як \n, який позначає розрив рядка:
let guestList = "Гості:\n * Іван\n * Петро\n * Марія";
alert(guestList); // список гостей в декілька рядків, як і вище
Наприклад, ці два рядки рівнозначні, просто написані по-різному:
let str1 = "Привіт\nСвіт"; // два рядки з використанням "символу нового рядка"
// два рядки з використанням звичайного нового рядка та зворотних лапок
let str2 = `Привіт
Світ`;
alert(str1 == str2); // true
Є й інші, менш поширені “спеціальні” символи.
|
Символ |
Опис |
|
\n |
Розрив рядка |
|
\r |
У текстових файлах Windows комбінація двох символів \r\n являє собою розрив рядка, тоді як в інших ОС, це просто \n. Так склалось з історичних причин, більшість ПЗ під Windows також розуміє \n |
|
\', \", \` |
Лапки |
|
\\ |
Зворотний слеш |
|
\t |
Знак табуляції |
|
\b, \f, \v |
Backspace, Form Feed, Vertical Tab – зберігаються для зворотної сумісності, зараз не використовуються |
Усі спеціальні символи починаються зі зворотного слеша \. Його також називають “символом екранування”.
Оскільки це так особливо, якщо нам потрібно показати зворотний слеш \ у рядку, нам потрібно подвоїти його:
alert( `Зворотний слеш: \\` ); // Зворотний слеш: \
Так звані “екрановані” лапки \', \", \` використовуються для вставки цих лапок в рядок, який обмежено таким же типом лапок.
Наприклад:
alert( 'Ім\'я моє — Морж!' ); // Ім'я моє — Морж!
Як бачите, ми повинні “екранувати” лапку зворотним слешем \', оскільки інакше це означало б кінець рядка.
Звісно, потрібно “екранувати” лише такі лапки, якими обрамлений рядок. Як елегантніше рішення, ми могли б замість цього скористатися подвійними або зворотними лапками:
alert( `Ім'я моє — Морж!` ); // Ім'я моє — Морж!
Окрім цих спеціальних символів, існує також спеціальна нотація для кодів Unicode \u…, вона використовується рідко та описана в додатковому розділі про Unicode.
2. Методи та функції роботи з рядками
Властивість length містить в собі довжину рядка:
alert( `Моє\n`.length ); // 4
Зверніть увагу, що \n – це один спеціальний символ, тому довжина рівна 4.
length – це властивість
Люди з досвідом роботи в інших мовах випадково намагаються викликати властивість, додаючи круглі дужки: вони пишуть str.length() замість str.length. Це не спрацює.
Зверніть увагу, що str.length – це числове значення, а не функція, додавати дужки не потрібно. Не .length(), а .length.
Отримати символ, котрий займає позицію pos, можна за допомогою квадратних дужок: [pos], або викликати метод str.at(pos). Перший символ займає нульову позицію:
let str = `Привіт`;
// перший символ
alert( str[0] ); // П
alert( str.charAt(0) ); // П
// останній символ
alert( str[str.length - 1] ); // т
alert( str.at(-1) );
Як бачите, перевага методу .at(pos) полягає в тому, що він допускає від’ємну позицію. Якщо pos від’ємне число, тоді позиція відраховується з кінця рядка.
Отже, .at(-1) означає останній символ, а .at(-2) – передостанній, тощо.
Квадратні дужки завжди повертають undefined для від’ємних індексів, наприклад:
let str = `Привіт`;
alert( str[-2] ); // undefined
alert( str.at(-2) ); // і
Ми також можемо перебрати рядок посимвольно, використовуючи for..of:
for (let char of "Привіт") {
alert(char); // П,р,и,в,і,т (char — спочатку "П", потім "р", потім "и" і так далі)
}
В JavaScript рядки не можна змінювати. Змінити символ неможливо.
Спробуємо показати на прикладі:
let str = 'Ой';
str[0] = 'о'; // помилка
alert( str[0] ); // не працює
Можна створити новий рядок замість старого, записавши його в ту саму змінну.
Ось так:
let str = 'Ой';
str = 'о' + str[1]; // замінюємо рядок
alert( str ); // ой
Методи toLowerCase() та toUpperCase() змінюють регістр символів:
alert( 'Інтерфейс'.toUpperCase() ); // ІНТЕРФЕЙС
alert( 'Інтерфейс'.toLowerCase() ); // інтерфейс
Або якщо ми хочемо перенести в нижній регістр конкретний символ:
alert( 'Interface'[0].toLowerCase() ); // 'і'
Існує декілька способів для пошуку підрядка.
Перший метод – str.indexOf(substr, pos).
Він шукає підрядок substr в рядку str, починаючи з позиції pos, і повертає позицію, де знаходиться збіг, або -1 якщо збігів не було знайдено.
Наприклад:
let str = 'Віджет з ідентифікатором';
alert( str.indexOf('Віджет') ); // 0, тому що 'Віджет' було знайдено на початку
alert( str.indexOf('віджет') ); // -1, збігів не знайдено, пошук чутливий до регістру
alert( str.indexOf("ід") ); // 1, підрядок "ід" знайдено на позиції 1 (..іджет з ідентифікатором)
Необовʼязковий другий параметр pos дозволяє нам почати пошук із заданої позиції.
Наприклад, перший збіг "ід" знаходиться на позиції 1. Щоб знайти наступний збіг, почнемо пошук з позиції 2:
let str = 'Віджет з ідентифікатором';
alert( str.indexOf('ід', 2) ) // 9
Щоб знайти усі збіги, нам потрібно запустити indexOf в циклі. Кожен новий виклик здійснюється з позицією після попереднього збігу:
let str = 'Хитрий, як лисиця, сильний, як Як';
let target = 'як'; // давайте знайдемо це
let pos = 0;
while (true) {
let foundPos = str.indexOf(target, pos);
if (foundPos == -1) break;
alert( `Знайдено тут: ${foundPos}` );
pos = foundPos + 1; // продовжуємо з наступної позиції
}
Той самий алгоритм можна записати коротше:
let str = "Хитрий, як лисиця, сильний, як Як";
let target = "як";
let pos = -1;
while ((pos = str.indexOf(target, pos + 1)) != -1) {
alert( pos );
}
str.lastIndexOf(substr, position)
Також є схожий метод str.lastIndexOf(substr, position), що виконує пошук від кінця рядка до його початку.
У ньому будуть перераховані збіги в зворотному порядку.
Існує незручність з indexOf в умові if. Ми не можемо помістити його в if таким чином:
let str = "Віджет з ідентифікатором";
if (str.indexOf("Віджет")) {
alert("Є співпадіння"); // не працює
}
В прикладі вище alert не відображається, оскільки str.indexOf("Віджет") повертає 0 (це означає, що він знайшов збіг у початковій позиції). Це правильно, але if вважає, що 0 – це false.
Тому нам потрібно робити перевірку на -1, як тут:
let str = "Віджет з ідентифікатором";
if (str.indexOf("Віджет") != -1) {
alert("Є співпадіння"); // тепер працює!
}
includes, startsWith, endsWith
Сучасніший метод str.includes(substr, pos) повертає true/false в залежності від того чи є substr в рядку str.
Цей метод доцільно використовувати, коли потрібно перевірити чи є збіг, але не потрібна позиція:
alert( "Віджет з ідентифікатором".includes("Віджет") ); // true
alert( "Привіт".includes("Бувай") ); // false
Необовʼязковий другий аргумент pos – це позиція з якої почнеться пошук:
alert( "Віджет".includes("ід") ); // true
alert( "Віджет".includes("ід", 3) ); // false, починаючи з 3-го символа, підрядка "ід" немає
Відповідно, методи str.startsWith та str.endsWith перевіряють, чи починається і чи закінчується рядок певним підрядком.
alert( "Віджет".startsWith("Від") ); // true, "Віджет" починається з "Від"
alert( "Віджет".endsWith("жет") ); // true, "Віджет" закінчується підрядком "жет"
В JavaScript є 3 метода для отримання підрядка: substring, substr та slice.
str.slice(start [, end])
Повертає частину рядка починаючи від start до (але не включно) end.
Наприклад:
let str = "stringify";
alert( str.slice(0, 5) ); // 'strin', підрядок від 0 до 5 (5 не включно)
alert( str.slice(0, 1) ); // 's', від 0 до 1, але 1 не включно, тому лише символ на позиції 0
Якщо другий аргумент відсутній, тоді slice поверне символи до кінця рядка:
let str = "stringify";
alert( str.slice(2) ); // 'ringify', з позиції 2 і до кінця
Також для start/end можна задати відʼємне значення. Це означає, що позиція буде рахуватися з кінця рядка:
let str = "stringify";
// починаємо з 4-го символа справа, і закінчуємо на 1-му символі справа
alert( str.slice(-4, -1) ); // 'gif'
str.substring(start [, end])
Повертає частину рядка між start та end (не включаючи end)…
Цей метод майже такий самий що і slice, але він дозволяє задати start більше ніж end (у цьому випадку він просто міняє значення start і end місцями).
Наприклад:
let str = "stringify";
// для substring ці два приклади однакові
alert( str.substring(2, 6) ); // "ring"
alert( str.substring(6, 2) ); // "ring"
// ...але не для slice:
alert( str.slice(2, 6) ); // "ring" (те саме)
alert( str.slice(6, 2) ); // "" (порожній рядок)
Відʼємні аргументи (на відміну від slice) не підтримуються, вони інтерпретуються як 0.
str.substr(start [, length])
Повертає частину рядка з позиції start, із заданою довжиною length.
На відміну від попередніх методів, цей дозволяє вказати довжину length замість кінцевої позиції:
let str = "stringify";
alert( str.substr(2, 4) ); // 'ring', починаючи з позиції 2 отримуємо 4 символа
Перший аргумент може бути відʼємним, щоб рахувати з кінця:
let str = "stringify";
alert( str.substr(-4, 2) ); // 'gi', починаючи з позиції 4 з кінця отримуєму 2 символа
Цей метод міститься в Annex B специфікації мови. Це означає, що лише рушії браузерного Javascript мають його підтримувати, і не рекомендується його використовувати. На практиці це підтримується всюди.
Давайте підсумуємо ці методи щоб не заплутатись:
|
Метод |
вибирає… |
відʼємні значення |
|
slice(start, end) |
від start до end (не включаючи end) |
дозволяє відʼємні значення |
|
substring(start, end) |
між start та end (не включаючи end) |
відʼємні значення інтерпретуються як 0 |
|
substr(start, length) |
length символів від start |
дозволяє відʼємні значення start |
Який метод вибрати?
Усі вони можуть виконати задачу. Формально substr має незначний недолік: він описаний не в основній специфікації JavaScript, а в Annex B, який охоплює лише функції браузера, які існують переважно з історичних причин. Тому не браузерні середовища, можуть не підтримувати його. Але на практиці це працює всюди.
З двох інших варіантів slice дещо гнучкіший, він допускає від’ємні аргументи та коротший в записі.
Отже, достатньо запамʼятати лише slice з цих трьох методів.
Як ми знаємо з розділу Оператори порівняння, рядки порівнюються символ за символом в алфавітному порядку.
Хоча, є деякі дивацтва.
Літера в малому регістрі завжди більша за літеру у великому:
alert( 'a' > 'Z' ); // true
Літери з діакритичними знаками “не в порядку”:
alert( 'Österreich' > 'Zealand' ); // true
Це може призвести до дивних результатів, якщо ми відсортуємо ці назви країн. Зазвичай люди очікують, що Zealand буде після Österreich.
Щоб зрозуміти, що відбувається, давайте розглянемо внутрішнє представлення рядків у JavaScript закодованих за допомогою UTF-16. Тобто: кожен символ має відповідний числовий код…
Існують спеціальні методи, які дозволяють отримати символ по коду і навпаки.
str.codePointAt(pos)
Повертає десяткове число, що є кодом символу на позиції pos:
// літери в різному регістрі мають різні коди
alert( "z".codePointAt(0) ); // 122
alert( "Z".codePointAt(0) ); // 90
alert( "z".codePointAt(0) ); // 122
alert( "z".codePointAt(0).toString(16) ); // 7a (if we need a hexadecimal value)
String.fromCodePoint(code)
Створює символ за його кодом code
alert( String.fromCodePoint(90) ); // Z
alert( String.fromCodePoint(0x5a) ); // Z (ми також можемо використовувати шістнадцяткове значення як аргумент)
Тепер давайте подивимося на символи з кодами 65..220 (латинський алфавіт і трохи більше), створивши з них рядок:
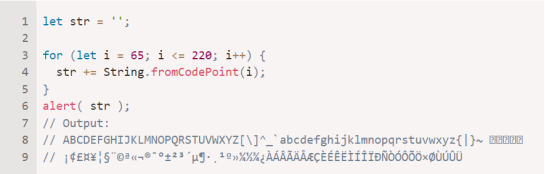
Бачите? Спочатку вводяться великі символи, потім кілька спеціальних, потім символи нижнього регістру та Ö ближче до кінця виводу.
Тепер стає очевидним, чому a > Z.
Символи порівнюються за їх числовим кодом. Більший код означає, що символ більше. Код для a (97) більший за код для Z (90).
Усі малі літери йдуть після великих, оскільки їхні коди більші.
Деякі літери, як-от Ö, стоять окремо від основного алфавіту. Тут його код більший за будь-що від a до z.
«Правильний» алгоритм порівняння рядків є складнішим, ніж може здатися, тому що для різних мов – різні алфавіти.
Отже, браузеру потрібно знати, яку мову використовувати для порівняння.
На щастя, усі сучасні браузери підтримують стандарт інтернаціоналізації ECMA-402.
Він забезпечує спеціальний метод для порівняння рядків різними мовами, дотримуючись їхніх правил.
Виклик str.localeCompare(str2) повертає ціле число, яке вказує, чи є str меншим, рівним чи більшим за str2 відповідно до правил мови:
Повертає відʼємне число, якщо str менше, ніж str2.
Повертає додатне число, якщо str більше, ніж str2.
Повертає 0, якщо вони рівні.
Наприклад:
alert( 'Österreich'.localeCompare('Zealand') ); // -1
Цей метод насправді має два додаткові аргументи, зазначені в документації, що дозволяє йому вказати мову (типово взяту з середовища, порядок букв залежить від мови) і встановити додаткові правила, як-от чутливість до регістру або чи слід розглядати різницю між "a" та "á".
Є 3 види лапок. Зворотні лапки дозволяють рядку охоплювати кілька ліній і застосовувати вбудовувані вирази ${…}.
Ми можемо використовувати спеціальні символи, такі як розрив рядка \n.
Щоб отримати символ, використовуйте: [ ] або метод at.
Щоб отримати підрядок, використовуйте: slice або substring.
Щоб перевести рядок у нижній/верхній регістри, використовуйте: toLowerCase/toUpperCase.
Щоб знайти підрядок, використовуйте: indexOf, або includes/startsWith/endsWith для простих перевірок.
Щоб порівняти рядки з урахуванням правил мови, використовуйте: localeCompare, інакше вони порівнюються за кодами символів.
Є кілька інших корисних методів у рядках:
str.trim() – видаляє (“обрізає”) пробіли з початку та кінця рядка.
str.repeat(n) – повторює рядок n разів.
…та багато іншого можна знайти в посібнику.
Рядки також мають методи пошуку/заміни регулярними виразами. Але це велика тема, тому пояснюється в окремому розділі Регулярні вирази.
Крім того, на даний момент важливо знати, що рядки базуються на кодуванні Unicode, і тому виникають проблеми з порівнянням, які ми описали вище. Більше про Unicode у розділі Юнікод, внутрішня будова рядків.
1) Переведіть перший символ у верхній регістр
Напишіть функцію ucFirst(str), яка повертає рядок str з першим символом у верхньому регістрі, наприклад:
ucFirst("василь") == "Василь";
Напишіть функцію checkSpam(str), яка повертає true, якщо str містить ‘viagra’ or ‘XXX’, інакше false.
Функція має бути нечутливою до регістру:
checkSpam('buy ViAgRA now') == true
checkSpam('free xxxxx') == true
checkSpam("innocent rabbit") == false
Створіть функцію truncate(str, maxlength), яка перевіряє довжину str і, якщо вона перевищує maxlength – замінює кінець str символом трьох крапок "…", щоб його довжина була рівною maxlength.
Результатом функції повинен бути урізаний (якщо потребується) рядок.
Наприклад:
truncate("Що я хотів би розповісти на цю тему:", 20) == "Що я хотів би розпо…"
truncate("Всім привіт!", 20) == "Всім привіт!"
У нас є вартість у вигляді "$120". Тобто: спочатку йде знак долара, а потім число.
Створіть функцію extractCurrencyValue(str), яка витягне числове значення з такого рядка та поверне його.
Приклад:
alert( extractCurrencyValue('$120') === 120 ); // true
Питання для самоконтролю
- Що таке рядок в JavaScript?
- Які типи даних використовуються для представлення рядків?
- Як оголосити змінну рядка?
- Які операції можна виконувати з рядками?
- Які методи і властивості доступні для рядків?
1


про публікацію авторської розробки
Додати розробку