Матеріал до уроку на тему "Сканування та розпізнавання"

Сканування та розпізнавання тексту
Що таке сканування й розпізнавання
Сканування – це процес одержання графічної копії оригінального зображення.
Сканувати документ можна по-різному. Наприклад, за допомогою сканера або фотоапарата. І в тому і в іншому випадках результатом буде
растровий графічний файл. Цей файл може бути кольоровим або чорно-білим,
мати різну роздільність, може бути представлений у різних форматах (найчастіше «*.jpg» або «*.tif»). Важливо розуміти головне: растровий файл – це набір точок. Те, що на екрані або друкованому аркуші він виглядає як текст, ще ні про що не свідчить. Обробити цей «текст» програмою Word або Excel неможливо. Усе, що ви зможете з ним зробити – це вставити його у вигляді готового об'єкта. Відкоригувати растровий файл можна лише у спеціальній програмі – графічному редакторі. При цьому працювати з ним можна як з малюнком, а не як з текстовим документом.
Зайвий раз пояснимо різницю між текстом й сканованим документом. Уявіть, що ви вводите документ до програми Word, набираючи його на клавіатурі. Щоразу, натискаючи клавішу, до комп'ютера потрапляє її код. Фактично цей код і зберігається у «вордовському» документі. У цьому випадку для кожної букви документа відомо її походження. Наприклад, перший символ цього абзацу має код «0194», це буква «В», другий – код «0224», це символ «а» і т.д. При друкуванні або виведенні тексту на екран виконується ВІЗУАЛІЗАЦІЯ документа. Тобто виходячи з кодів, що є в тексті Word формує їх графічне зображення, іншими словами, «промальовує» букви. Коли ви коригуєте документ у програмі Word, ви змінюєте коди символів у документі. Саме тому одне натискання клавіші може змінити лише один символ. У графічному зображенні цього немає. Сканер нічого не друкує. Він вводить піксели (крапки) зображення. Будучі розташовані у певному порядку, ці пікселі виглядають як текст, і не більше того. Той факт, що якась частина цього зображення – це символ «В», якась частина – символ «а» комп'ютеру невідома. Для нього ці символи – усього лише вибудуваний певним чином набір пікселів. Тому й відредагувати ці піксели програмою Word не можна.
Для того, щоб перетворити графічний файл до текстового документу, його потрібно розпізнати. Цим займаються спеціальні програми оптичного розпізнавання образів (OCR). Однією з найпоширеніших програм цього класу є FineReader. Незважаючи на відмінності у деталях, мета у цих програм одна.
Вони аналізують зображення, намагаючись знайти фрагменти із якимось змістом. Це можуть бути символи тексту, таблиці, малюнки. Тобто програма розпізнавання намагається з'ясувати структуру документа: знайти букви, слова, речення, орієнтуючись на специфіку їх зовнішнього вигляду. Потім вона формує текстовий документ, перевіряє його за системою словників, граматичних правил й пропонує користувачеві для остаточного контролю. Коли перевірку завершено, результат роботи програми розпізнавання можна зберегти у формат текстового процесора Word або електронної таблиці Excel. І тільки після цього ви одержите «нормальний» документ, з яким можете робити все, що завгодно.
Звичайно, на практиці не все так просто. Алгоритм розпізнавання – процес складний, у випадку неякісних зображень програма розпізнавання припуститься чисельних помилок. Щоб мінімізувати їх кількість, треба чітко уявляти, які мають бути зображення для доброго розпізнавання, як їх можна виправити у графічному редакторі, яким чином треба організувати сам процес розпізнавання.
3. Які зображення можна розпізнати
Щоб процес розпізнавання був успішним, графічне зображення повинне відповідати певним вимогам, а саме:
– графічний файл повинен мати роздільність десь близько 300 dpi. До речі, це «стандартна» роздільність для цифрового фотоапарата;
– лінійний розмір зображення при цій роздільності повинен бути
зіставленим з оригіналом. Малоймовірно, що вам удасться розпізнати сторінку документа з дозволом 300 dpi розміром з поштову марку;
– для розпізнавання тексту зображення може бути чорно-білим або у відтінках
сірого. Переваг роботи з кольоровими зображеннями в цьому випадку немає. Це, так сказати, технічні вимоги до малюнків для розпізнавання. Зрозуміло, є й інші не менш важливі умови для успішного виконання цієї роботи. Наприклад, зображення повинне бути досить контрастним, букви – із чітко обкресленими краями. Любий «сміття» на сканованому зображенні у вигляді позначок олівцем, плям, дефектів паперу програма розпізнавання спробує ідентифікувати як символи. Нічого гарного із цього не вийде. По великому рахунку, усунення подібних дефектів – не наше завдання. Ми повинні постаратися зробити так, щоб їх було якнайменше.
4. Як розпізнати документ у програмі FineReader
Спочатку навчимося розпізнавати якісні зображення. Тобто такі, що не потребують обробки. Такі зображення можуть бути отримані зі сканера, або внаслідок копіювання фрагментів екрана. Для прикладу ми візьмемо для розпізнавання фрагмент тексту з таблицею, що зображений на рис. 1.

Для розпізнавання будемо використати програму «FineReader 8.0» компанії ABBYY ( http://www.abbyy.ua/ ), скачавши демонстраційну версію з http://www.abbyy.ru/Download/.
4.1. Інтерфейс програми FineReader
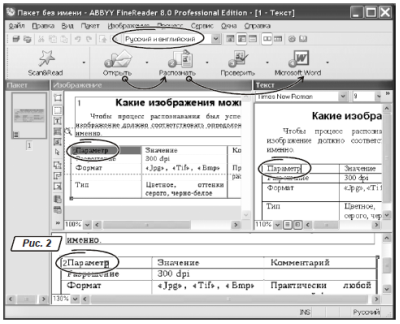
Вікно програми зображено на рис. 2. У ньому представлено меню, під ним – панелі інструментів.
Нижче панелі інструментів знаходяться п'ять великих іконок для керування програмою, а саме: «Scan&Read», «Открыть», «Распознать», «Проверить», «Microsoft Word». Основна частина вікна розбита на чотири області. Перелічимо їх у порядку зліва-направо й зверху-вниз. У лівій частині вікна міститься область сторінок документа. Кожна сторінка – це окреме зображення. Праворуч від області сторінок розташоване віконце «Изображение». У ньому ми бачимо фрагмент відсканованого документа, а також його розмітку (про неї поговоримо трохи пізніше). У правій частині вікна показаний результат розпізнавання. Це – текстовий документ, його можна правити прямо в програмі FineReader.
У нижній частині вікна розташована область зі збільшеною копією зображення. Між областю сторінок і віконцем «Изображение» перебуває робоче меню для розмітки малюнка перед його розпізнаванням.
4.2. Послідовність дій щодо розпізнавання документу
Щоб розпізнати сканований документ, потрібно зробити так:
1. Завантажити одне або декілька зображень до програми FineReader.
2. Відредагувати зображення, щоб очистити його від «сміття», усунути перекручування рядків й т. і. Цей етап потрібен не завжди.
3. Розмітити зображення, тобто вказати, Як FineReader повинен інтерпретувати окремі ділянки малюнка. Звичайно така операція потрібна при складному форматуванні документа. Для простих випадком операцію розмітки FineReader прекрасно виконує в автоматичному режимі. 4. Розпізнати документ.
5. Переглянути результат роботи. Якщо FineReader помилився, можна відредагувати документ або поправити розмітку й повторити розпізнавання.
6. Імпортувати результат розпізнавання до зовнішнього додатку, наприклад, до програми Word або Excel.
4.3. Завантаження зображень
У нашому випадку дані для розпізнавання перебувають на жорсткому
диску у вигляді графічних файлів. Натискаємо кнопку «Открыть» (на рис. 2 вона зображена з номером «1»). З'явиться вікно Провідника. У ньому знаходимо папку, виділяємо потрібні файли й клацаємо на кнопці «Открыть» або натискаємо «Enter». Завантажені зображення з'являться в області сторінок.
Для швидкого завантаження зображень користуйтеся комбінацією «Ctrl+O» (англійська буква «O»). Можете також скористатися меню «Файл → Открыть».
Кнопка «Scan&Read» служить для початку процесу сканування документа. Якщо ви користуєтеся сканером, включіть його, покладіть документ і натисніть «Scan&Read». Подальша робота залежить від моделі сканера й має бути викладена в інструкції до нього. Через цю кнопку можна й завантажити документ. Клацніть на маленькому трикутнику в лівій частині іконки «Scan&Read». Розкриється список можливих дій. Серед них буде й операція «Открыть и распознать». Точно так, розкривши список дій кнопки «Открыть», ви побачите рядок «Сканировать изображение… Ctrl+K»... Таким чином, кнопки «Scan&Read» й «Открыть» багато у чому взаємозаміняють одна одну.
4.4. Автокоригування зображень
Операції коригування зображення зосереджені в меню «Изображение». Розберемо ті можливості, які доводиться використати найчастіше.
ПОВОРОТ ЗОБРАЖЕННЯ. Текст при розпізнаванні повинен бути зорієнтований «зверху вниз» і випливати «зліва направо». Якщо сторінка документа сканована з поворотом, її прийде переорієнтувати. Для цього ввійдіть в «Изображение → Повернуть/Отразить изображение». З'явиться меню з п'яти пунктів: «Повернуть по часовой стрелке», «Повернуть против часовой стрелки», «Повернуть на 1800», «Зеркально отразить относительно вертикали», «Зеркально отразить относительно горизонтали». На практиці звичайно вистачає перших двох можливостей.
КОРИГУВАННЯ РОЗДІЛЬНОЇ ЗДАТНОСТІ. Якщо зображення скановано з «неправильним» розділенням, зверніться до меню «Изображение → Исправить разрешение» або «Ctrl+Shift+T». У вікні встановіть потрібні параметри. Звичайне значення за замовчуванням «300dpi» змінювати не слід. Якщо всі сторінки скановані з низьким розділенням, переустановіть перемикач «Исправить разрешение» у положення «Всех изрображений пакета».
ОЧИЩЕННЯ ЗОБРАЖЕНЬ ВІД ДЕФЕКТІВ. Тепер спробуємо поліпшити якість картинки. Відразу скажемо: серйозні дефекти зображення Finereader не виправить. Він може прибрати лише незначні дефекти, такі як смітинки на папері, невеличкі плями й т. і. Причому цю операцію він зробить інтелектуально: текст залишиться у первісному стані, його пошкоджено не буде. Щоб поліпшити зображення і прибрати з нього незначні дефекти треба діяти так:
– виділити одну або кілька сторінок документа;
– викликати меню «Изображение → Обработать изображение → Очистить изображение от мусора».
«ВИРІВНЮВАННЯ» РЯДКІВ. Один з типових дефектів сканування – це деформація рядків тексту. Ось приклад: при скануванні книги текст, що міститься біля її переплету звичайно виглядатиме нерівним. У цьому випадку рядки тексту на сканованому зображенні будуть виглядати не прямими, а трохи деформованими. Виправити такий дефект може операція усунення деформації рядків. Правда, упоратися із цим завданням вона зможе не завжди!
Щоб вирівняти рядки у відсканованому зображенні зробіть так.
– виділіть одну або кілька сторінок документа;
– зверніться до меню «Изображение → Обработать изображение → Устранить искажение строк».
Користуйтесь інструментом вирівнювання рядків обережно. У деяких випадках він може відробити неправильно. Тому не застосовуйте вирівнювання відразу до всіх сторінок документа. Обробляйте їх по однієї, щораз переглядаючи отриманий результат. Цими можливостями ми поки що й обмежимося.
4.5. Розмітка документу
Інформацію в електронному документі можна умовно розділити на три категорії: текст, таблиця й малюнок. При розпізнаванні програмі FineReader бажано «знати», з чим вона має справу. У принципі, аналізуючи сторінку, виявити її структуру FineReader може й самостійно. Але при складному форматуванні можливі помилки. Наприклад, якщо в документ вставлене зображення вікна Windows. FineReader напевно спробує розпізнати текст меню цього вікна, хоча за змістом нічого такого робити не потрібно.
У простих випадках опирайтеся на автоматичну розмітку тексту. Якщо форматування йде в декількох колонках, перемежовується малюнками, таблицями – робіть розмітку самі. Виправляти помилки FineReader-а вийде довше. Тому треба освоїти «ручну» розмітку документа, тим більше, що зробити це зовсім не складно.
Подивіться на панель інструментів розмітки ліворуч від області сторінок.
Почнемо з іконки з буквою «Т»: це інструмент для визначення текстового блоку. Клацніть на іконці лівою кнопкою миші. Поставте покажчик на зображенні документа там, де повинен починатися фрагмент тексту. Утримуючи натиснутої ліву кнопку миші, обведіть текстовий блок. Відпустите ліву кнопку миші. У документі з'явилася прямокутна область зеленого кольору. Вона повинна охоплювати фрагмент зображення, що FineReader тепер буде розглядати як текст. На рис. 2 текстовий блок охоплює всю частину документа, за винятком таблиці. Він позначений номером 1.
Щоб видалити блок розмітки потрібно виділити його щигликом миші й нажати клавішу «Del». Щоб змінити розмір блоку виділите його й розтягніть за кут або границю так, як ви міняєте розмір вікна Windows.
Таким же чином ви можете виділити блок з таблицею або малюнком. Ці іконки розташовані нижче інструмента виділення текстового блоку. З областями малюнків все зрозуміло: ці ділянки зображення FineReader розпізнавати не буде.
Він перенесе їх у результуючий документ «як є». А от з таблицями має сенс познайомитись докладніше. Зазвичай розпізнавання таблиці робиться так.
- Вибираємо інструмент визначення блоку з таблицею.
 - Акуратно обводимо фрагмент зображення, де міститься таблиця. Зайвий простір при цьому краще не чіпати, але й зовнішня границя таблиці повинна повністю перебувати всередині блоку.
- Акуратно обводимо фрагмент зображення, де міститься таблиця. Зайвий простір при цьому краще не чіпати, але й зовнішня границя таблиці повинна повністю перебувати всередині блоку.
- Клацаємо усередині створеного блоку правою кнопкою миші. З контекстного меню (рис. 3) вибираємо «Анализ структуры таблицы».
- Переглядаємо результат розмітки. Особливу увагу звертаємо на те, як розташувались окремі осередки таблиці. Для цього є сенс послідовно клацати лівою кнопкою миші по осередках таблиці в області розмітки й аналізувати правильність їхнього розташування.
- Якщо FineReader усе зробив правильно, переходимо до наступного етапу роботи. А що робити в тому випадку, якщо при розмітці таблиці є певні помилки?
Наприклад, FineReader не розпізнав бліду лінію границі й об'єднав декілька осередків в один? Для цього на панелі розмітки блоків є інструменти:
«Добавить вертикальную линию», «Добавить горизонтальную линию» й «Удалить линии». Користуватися ними дуже просто. Клацніть на іконці «Добавить вертикальную линию». Переведіть покажчик миші у віконце «Изображение» на таблиці. Разом з покажчиком по зображенню буде переміщатися вертикальна лінія розмітки. Поставте її на потрібне місце й клацніть лівою кнопкою миші. Таким же чином додайте всі відсутні вертикальні лінії в розмітці таблиці. Щоб закінчити роботу в режимі додавання ліній виберіть інший інструмент розмітки.
По такому ж алгоритмі розберіться з горизонтальними лініями. Інструмент «Удалить линии» допоможе стерти зайві лінії розмітки таблиці.
При роботі з таблицями часто доводиться поєднувати або розділяти окремі осередки таблиці. Зробити це простіше всього через праву кнопку миші. Поставите покажчик на осередок таблиці. Клацніть правою кнопкою миші. З контекстного меню (рис. 3) виберіть пункт «Ячейки таблицы». У ньому є три розділи: «Разбить ячейки», «Объединить ячейки», «Объединить строки». Якщо FineReader помилково злив кілька осередків в одну, скористайтеся з можливості «Разбить ячейки». Якщо буде потрібно об'єднання осередків в одне ціле, виділіть їх і зверніться до пункту «Объединить ячейки» контекстного меню.
4.6. Розпізнаємо зображення
Коли розмітка сторінок завершена, натисніть «Ctrl+Shift+R» – розпізнати всі сторінки. Цю дію можна виконати через меню «Процесс → Распознать → Распознать все» або розкривши список доступних дій кнопки «Распознать».
Стежте за тим, яка мова встановлена для розпізнавання. Вибрати мову можна прямо на панелі інструментів FineReader. Наприклад, на рис.2 встановлена пара «Русский и английский». Щигликом миші розкрийте список і виберіть варіант, що підходить для вашого випадку.
Результат розпізнавання можна подивитися у віконці «Текст» (рис. 2). Уважно прогляньте його. Спочатку переконаєтеся, що FineReader правильно обробив структуру документа. Якщо це не так, відкоригуйте розмітку й заново розпізнайте сторінку.
При повторному розпізнаванні не обов'язково заново обробляти весь документ. Ви можете обмежитися поточною або декількома виділеними сторінками. Виділіть сторінку й клацніть на кнопці «Распознать» або натисніть «Ctrl+R».
4.7. Зберігаємо результат
Робота над великими документами може забрати багато часу й проходити в декілька сеансів. Щоб зберегти результат роботи в програмі FineReader використовується поняття пакет. Пакет поєднує вихідні зображення, їхню розмітку, результати обробки в тім стані, що було на момент створення пакета.
Зберегти пакет можна через меню «Файл → Сохранить пакет как…». З'явиться вікно, ідентичне вікну Провідника. Вибираємо папку, вказуємо ім'я пакета й результат збережений.
Пакет являє собою безліч файлів. Щоб не вносити сум'яття, не зберігайте пакет у папку, де вже є якісь дані. Краще завжди зберігати пакет в окремому каталозі.
4.8. Імпортуємо результат
Імпорт потрібний для збереження результатів у зовнішньому додатку або буфері обміну. Щоб зберегти поточну сторінку в Word клацніть на останній іконці з номером 4 і написом «Microsoft Word» (рис. 2). Відкриється вікно Word з розпізнаним документом. Це не єдиний спосіб імпортування даних. Клацніть на значку розкриття списку кнопки «Microsoft Word». З'являться такі варіанти:
«Мастер сохранения результатов», «Сохранить страницы…», «Передать страницы в…», «Передать все страницы в…», «Опции».
Через «Сохранить страницы…» можна записати результат розпізнавання на диск. При записі є можливість вибрати всі або поточну сторінки, а також визначити формат файлу для збереження.
Звичайно користуються пунктами «Передать страницы в…» і «Передать все страницы в…». Ці дві можливості відрізняються тільки тим, що в першому випадку імпортується поточна або кілька виділених сторінок, у другому випадку FineReader передасть всі сторінки документа. Обоє меню містять кілька розділів. Їхня кількість залежить від установлених програм на вашому комп'ютері. Можна обмежитися трьома: «Microsoft Word», «Microsoft Excel» й «Буфер обмена». Виберіть один із зазначених пунктів. FineReader викличе додаток і передасть у нього результат розпізнавання.
4.9. Розпізнавання таблиці складної структури
Таблиці неоднорідної структури – звичайна річ у практиці менеджера, економіста і бухгалтера. Тому, завершуючи тему розпізнавання документів, дамо пораду, як з ними працювати.
Перш ніж розпізнавати складну таблиці постарайтеся визначити її «базову структуру». Визначити той «оптимальний» набір рядків і колонок, що згодом мінімізує витрати на поділ й об'єднання осередків. Коли структура проясниться, зробіть ручну розмітку таблиці.
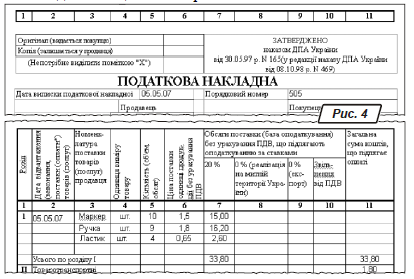
Вибір структури дуже важливий. Не поспішаєте починати обробку документа, поки не продумаєте це питання. Гляньте для приклада на бланк податкової накладної, зображений на рис. 4. Спробувавши розпізнати документ «напряму», в автоматичному режимі, ви, швидше за все, одержите кашу з текстових полів, фрагментів таблиць і т.п. Упорядкувати таку абракадабру буде складніше, ніж набрати бланк «з нуля». У той же час проблема вирішується просто.
Більшість частин документа вкладається в 11 колонок. Вони пронумеровані й показані у верхній частині малюнка. При розмітці виділили блок типу «Таблица». Інструментами «Добавить вертикальную линию», «Добавить горизонтальную линию» розмітили таблицю. Зазначте, зробили це вручну. Після цього пройшлися по таблиці, поєднуючи окремі осередки заголовка в групи. Результат розпізнавання такого складного документа був чудовий. Нагадаємо, що поєднувати й розділяти осередки зручно через праву кнопку миші (пункти «Разбить ячейки», «Объединить ячейки»). Якщо ви вдало вибрали структуру для ручної розмітки, найбільш складні таблиці вам не страшні.

про публікацію авторської розробки
Додати розробку