Сучасні методи пошуку інформації в системі Internet.

Тема роботи: Сучасні методи пошуку інформації в системі Internet.
Анотація
У мережі Інтернет зосереджено необмежену кількість інформації, серед якої велику частину займають освітні інформаційні ресурси. Проте часто потрібну інформацію дуже складно знайти, бо вона не достатньо структурована, орієнтуватися у просторі мережі Інтернет досить складно і тому цей процес займає дуже багато часу. В цій роботі розглянуті основні види інформації, пошукових систем та способів найбільш ефективно «відокремлювати зерна від полови»
|
|
Сторінка |
|
Анотація |
3 |
|
Зміст |
4 |
|
Вступ |
5 |
|
Теоретична частина |
6 |
|
Інформаційно - пошукові системи Інтернет |
6 |
|
Складові пошукових систем |
9 |
|
Характеристики пошукових систем |
12 |
|
Проблеми використання пошукових систем Інтернет |
17 |
|
Підвищення ефективності пошуку інформаційних ресурсів Інтернету |
20 |
|
Практична частина |
22 |
|
Висновки |
32 |
|
Список використаної літератури |
33 |
Зміст
Вступ
Поява всесвітньої мережі Інтернет називають одним з важливих досягнень сучасної цивілізації. І справа не тільки в тім, що вже зараз Інтернет - це практично нескінченний інформаційний ресурс, а в тім, що він є дійсно всесвітнім джерелом знань, глобальним і загальнодоступної по своїй суті. І це джерело постійно поповнюється все новими і новими знаннями, поєднує їх, дає можливість використовувати необхідну інформацію тоді, коли вона дійсно потрібна.
Простір Інтернет воістину величезний, і немає необхідності докладно розповідати про те, що саме можна в ньому знайти. В даний момент уже практично неможливо перелічити всі області знань, що охоплює ця всесвітня мережа. Однак не секрет, що для більшості користувачів перша ж спроба пошуку чого-небудь у цьому морі інформації звичайно розчаровує.
Дійсно, разом зі збільшенням обсягів доступної інформації усе гостріше встає проблема пошуку дійсно потрібних користувачу даних. Варто визнати, що це дійсно складна задача, оскільки обсяг даних, доступних через Інтернет, воістину величезний, а серйозної класифікації представленої там інформації просто не існує
Теоретична частина
Інформаційно - пошукові системи Інтернет
За тисячі років свого існування і безперервного потягу передової його частини до наукових знань, людство накопичило величезну кількість інформації з різноманітних областей науки, техніки культури і т.п. Попри всі намагання до наукових знань найбільшою перепоною до швидкого прогресу, на мій погляд була не відсутність знань, а відсутність інформації про те, що такі знання вже є, хтось зробив уже такі дослідження і треба всього лиш отримати інформацію про них. Таким чином конче необхідним було об'єднати всі цю інформацію про життєдіяльність людей і зробити її досяжною для тих, кому вона потрібна. Ситуація змінилася докорінно з появою Інтернету. Він зумів об'єднати знання сотень поколінь землян в єдиний інформаційний простір, що відкритий для кожного, хто б цього забажав. Неможливо перерахувати що є в Інтернеті ( власне як і чого нема).
Ці глобальні інформаційні ресурси знаходяться в стані постійної систематизації, тобто людство постійно вишукує найбільш оптимальні способи зберігання і пошуку необхідної інформації. Для цього в Інтернеті існує купа пошукових і файлових серверів, DNS серверів. В Інтернеті є багато ресурсів, але офіційній перелік їх відсутній. Кожен хто має вихід в Інтернет може в любий момент, нікому не кажучи створити новий ресурс, тому складність заключається в тому, щоб з'ясувати, що ж насправді є в Інтернет. Треба пам'ятати, що Інтернет - динамічна система і що її період напіврозпаду складає близько чотирьох років.
Це значить, що за рік ресурси в мережі Інтернет старіє приблизно 25% даних. Ще одна проблема в тому, що якість мережевих ресурсів не однакова. Одним словом в глобальній інформаційній мережі приховані глобальні інформаційні ресурси і отримати їх може кожен, але найбільшого успіху досягне той, хто знає як це зробити.
Пошук інформації в Інтернет неможливий без спеціальних механізмів, що допомагають людині знайти в цьому безмежному просторі потрібну інформацію. І, звичайно ж, такі механізми існують. З'явившись у середині 70-х років, вони одержали назву інформаційно-пошукових систем, і з тих пір постійно удосконалюються.
Як вже говорилося, пошукові системи існують уже давно. З появою Інтернет вони відразу ж зайняли своє місце й у цій області інформаційних технологій. У загальному випадку інформаційно-пошуковою системою називається система, що забезпечує пошук і добір необхідних даних на основі інформаційно-пошукової мови і відповідних правил.
На сьогоднішній день" всесвітнє павутиння" включає декілька десятків (по різним оцінкам - від 50 до 80) мільйонів серверів, на кожному з яких доступно від декількох мегабайт до десятків гігабайт інформації. Для пошуку незліченної інформації в Інтернеті на допомогу приходять тематичні та індексні пошукові системи.
Типовий приклад тематичного каталогу - пошукова система Yahoo (http://www.yahoo.com). Це спеціалізований сервер WWW, на якому зберігаються списки інших серверів з їх стислими описами. Інформація згрупована за смисловими категоріями і має ієрархічну структуру; наприклад, на цьому сервері можна знайти розділи "Комп'ютери та Інтернет-мультимедіа - Журнали", "Розваги - Музика - Групи і виконавці - Елтон Джон", "Країни - Україна - Бізнес в Україні", а також безліч інших. Передбачена на сервері система шукає дані тільки в каталозі Yahoo і не заглядає на сторінки згаданих в ньому серверів. Користуватися такою системою (а також будь-якою іншою, аналогічною їй, наприклад, списком російських серверів WWW за адресою http://www.ru) надзвичайно просто. Треба знайти потрібний розділ і після цього - підходящий сервер за його стислим описом, наведеним там же. Такі каталоги мають недоліки: низька оперативність зміни інформації, відносна складність пошуку (за стислою та інколи помилковою адресою сервера), порівняно невелика "область охоплення" простору WWW.
Існує більш зручний і ефективний засіб пошуку необхідних відомостей. Це так звані індексні пошукові системи (пошукові механізми - search engines). Основою їх є спеціалізовані комп'ютери, що періодичні проводять індексацію документів на серверах "всесвітнього павутиння", і дозволяють шукати інформацію на цих серверах за одним або кількома ключовими словами і, можливо, за деякими додатковими ознаками.
До кінця 1997 р. в мережі Інтернет налічувалося близько двох тисяч різноманітних пошукових серверів, які відрізняються один від одного типом, спеціалізацією, сферою охоплення (кількістю індексованих сторінок) і популярністю. Більша частина цих серверів має порівняно вузьку спеціалізацію - наприклад, пошук музики в форматі МР3 або пошук інформації на серверах у галузі молекулярної хімії. Існує декілька надзвичайно популярних універсальних пошукових серверів, призначених для пошуку за ключовими словами на якомога більшому числі сторінок системи WWW. Найбільш відомими є сервери Google (https://www.google.com.ua), AltaVista (http://altavista.digital/com), InfoSeek (http://www.infoseek.com), Excite (http://www.excite.com), HotBot (http://www.hotbot.com), Lycos (http://www. lycos. com).
Принцип дії більшості таких серверів простий. Для пошуку інформації використовується індекс, створений спеціальною програмою-роботом. Програма-робот періодично обходить відомі їй адреси мережі, зчитує з них сторінки, що зберігаються WWW, індексує всі слова з усіх сторінок (разом з адресами URL) і розміщує їх в загальний індекс. Для зберігання цього індексу потрібен величезний обсяг пам'яті, а для його обробки - чимала обчислювальна потужність. Наприклад, основний механізм одного з найпотужніших пошукових серверів AltaVista (повного індексу, що претендує на всю мережу Інтернет), включає 16 потужних комп'ютерів Alpha Server 8400 5/440. На кожному з цих комп'ютерів встановлено по 12 центральних процесорів, 8 гігабайт оперативної пам'яті (обсяг, еквівалентний обсягу пам'яті 500 стандартних сучасних персональних комп'ютерів) і дисковий масив RAID ємкістю 300 гігабайт. Вся ця система з'єднана з магістральною мережею Інтернет каналом зв'язку з пропускною спроможністю 100 Мбіт/с. Загальний обсяг на сервері індексних файлів, що зберігаються, в яких виробляється пошук, - понад 200 гігабайт.
Ще одна категорія пошукових серверів - так звані "метапошукові" сервери (метасервери). Найбільш відомий з них - WebCrawler (http://www.webcrawler.com). Сервери такого типу передають отриманий від користувача запит на пошук інформації іншим пошуковим серверам, об'єднують результати пошуків і повертають результат користувачу. Застосування подібних серверів має як переваги, так і недоліки. Найцінніша перевага полягає в економії часу на однотипових запитах до різноманітних серверів. Проте, позначки в синтаксисі запитів змушують користувачів метасерверів дотримуватися найзагальнішої форми запиту, без можливості вдаватися до потужніших засобів пошуку. Незважаючи на це, метасервери - непоганий засіб оперативної оцінки того, наскільки широко представлена в системі WWW та чи інша інформація.
Складові пошукових систем
Пошукові cистеми зазвичай мають три компоненти:
· агент (павук, кроулер або робот), який переміщується по мережі і збирає інформацію;
· база даних, яка містить інформацію, що зібрано павуками;
· пошуковий механізм, який користувачі використовують як інтерфейс для взаємодії з базою даних.
Засоби пошуку типу агентів, павуків, кроулерів і роботів використовуються для збору інформації про документи, які знаходяться в мережі Інтернет. Це спеціальні програми, які займаються пошуком сторінок в мережі, збирають гіпертекстові посилання з цих сторінок і автоматично індексують інформацію, яку вони знаходять для побудови бази даних. Кожний пошуковий механізм має власний набір правил, якими визначається збір документів.
· Агенти є найінтелектуальнішими з пошукових засобів. Вони можуть робити більше, ніж просто шукати: вони можуть виконувати транзакції від імені користувача. Вже зараз вони можуть шукати сайти специфічної тематики і повертати списки сайтів, відсортованих за їх відвідуваністю. Агенти можуть обробляти вміст документів, знаходити та індексувати інші види ресурсів, не лише сторінки. Вони можуть бути запрограмовані для витягання інформації з вже існуючих баз даних. Незалежно від інформації, яку агенти індексують, вони передають її назад до бази даних пошукового механізму.
· Павуки здійснюють загальний пошук інформації в Інтернет. Павуки повідомляють про зміст знайденого документа, індексують його і добувають підсумкову інформацію. Вони також переглядають заголовки, деякі посилання і відправляють проіндексовану інформацію до бази даних пошукового механізму.
· Кроулери переглядають заголовки і повертають тільки перше посилання.
· Роботи можуть бути запрограмовані таким чином, щоб переходити по різним посиланням різної глибини вкладеності, виконувати індексацію і перевіряти посилання в документі. Але, вони можуть застрягати в циклах, адже, проходячи за посиланнями, їм потрібні значні ресурси мережі. Існують методи, що забороняють роботам пошук по сайтах, власники яких не бажають, щоби вони були проіндексовані.
Агенти збирають та індексують різні види інформації. Деякі, наприклад, індексують кожне окреме слово у документі, в той час як інші індексують тільки 100 найбільш важливих слів в кожному документі, індексують розмір документу і кількість слів в ньому, назву, заголовки і підзаголовки і так далі. Вигляд побудованого індексу визначає, який пошук може бути проведений пошуковим механізмом і як отримана інформація буде інтерпретована.
Агенти знаходять інформацію, після чого її розміщують в базі даних пошукового механізму. Адміністратори пошукових систем визначають, які сайти або типи сайтів агенти мають відвідати та проіндексувати. Проіндексована інформація відправляється до бази даних пошукового механізму.
Користувачі можуть розміщувати інформацію прямо в індексі, заповнюючи особливу форму для того розділу, в який вони хотіли б помістити свою інформацію. Ці дані передаються базі даних. Коли користувач хоче знайти інформацію, доступну в Інтернет, він відвідує сторінку пошукової системи і заповнює форму, що деталізує потрібну йому інформацію. Тут можуть використовуватись ключові слова, дати та інші критерії. Критерії в формі пошуку повинні відповідати критеріям, які використовуються агентами при індексації інформації, яку вони знайшли при переміщені по мережі. База даних відшукує предмет запиту, що базується на інформації, яка вказана в заповненій формі, і виводить відповідні документи, що підготовані базою даних. Для того, щоб визначити порядок, в якому перелік документів буде показано, база даних застосовує алгоритм ранжування. В ідеальному випадку, розташованими першими в списку будуть документи, що є найбільш релевантними до запиту користувача.
Релевантність - основне поняття при індексації документа в пошукових системах. Релевантність - міра відповідності, тобто це відповідність змісту знайденої сторінки до запиту користувача. Але комп'ютер - не людина, і тому пошукові системи використовують спеціальні алгоритми для визначення релевантности. Теоретичних методів визначення релевантності більш ніж 20. Але виділяють два основні напрями: лінгвістичне (Мета) і статистичне (Google).
Основні українські пошукові системи (зокрема Мета) використовують лінгвістичний напрям, тобто пошуковий робот, переглядаючи сторінку, звертає увагу на "літературність" її написання ("чом ти не прийшов" буде більш релевантною, ніж "чом ти не травень прийшов").
Різні пошукові системи використовують різні алгоритми ранжування, однак основними принципами визначення релевантності є наступні:
· Кількість слів запиту у текстовому вмісті документу (тобто в html-коді).
· Теги, в яких ці слова розташовуються.
· Місцеположення шуканих слів у документі.
· Питома вага слів, відносно яких визначається релевантність, у загальній кількості слів документу.
Ці принципи застосовуються всіма пошуковими системами. А наведені нижче використовуються деякими, але достатньо відомими (наприклад, AltaVista).
· Час - як довго сторінка знаходиться в базі пошукового сервера. Спочатку здається, що це недолугий принцип. Але в Інтернет існує багато сайтів, час життя яких складає близько місяця. Якщо ж сайт існує досить довго, це значить, що його власник є досвідченим за даною темою і користувачу більше підійде сайт, що існує вже кілька років, ніж той, який з'явився тиждень тому за цією ж темою.
· Індекс цитованості - як багато посилань на дану сторінку веде з інших сторінок, що зареєстровані у базі пошуковика.
База даних виводить ранжований таким чином перелік документів з HTML і повертає його користувачу, який зробив запит. Різні пошукові механізми вибирають різні способи показу отриманого переліку - деякі відображають лише посилання, інші виводять посилання з декількома першими реченнями документу або заголовок документу разом з посиланням.
Характеристики пошукових систем
Українська пошукова система "МЕТА"
Українська пошукова система "МЕТА" є найвідомішим проектом компанії - ЗАТ «МЕТА» - розробника пошукових і інформаційних рішень. Сьогодні "МЕТА" -- один з найбільш відвідуваних українцями сайтів і найбільший рекламний майданчик України.«Мета.ua» - проект український, він створений і працюватиме тільки для України.А технології, які були створені в процесі роботи, цілком можуть бути використані в інших країнах. Пошукові технології компанії працюють у внутрішніх мережах Верховної Ради і кабінету міністрів України, на сайтах національного банку України, фонду Разумкова, сайті Віктора Ющенка. За 2005 рік аудиторія збільшилася більш ніж в два рази. «Мета» - це безкоштовний сервіс, який не має ніяких зобов'язань перед власниками сайтів і не гарантує «правильного» місця видачі.Нові сервіси пошукової системи "МЕТА" можна поділити на три типи: пошукові, інформаційні і комунікаційні. З пошукових сервісів хочеться відзначити «Метановини». Це найпопулярніший розділ після великого пошуку і каталогу. Зараз там збираються новини від більше як 200 українських інтернет-джерел, близько 10 000 новин в день. Весь цей масив в режимі реального часу індексується, групується по темах і стає доступним для пошуку.
«Пошук рефератів». Практично єдиний сервіс в СНД, що дозволяє шукати не тільки по назві і опису, але і по всьому тексту. В період сесій і іспитів студенти і школярі активно користуються цим сервісом.
З останніх пошукових проектів - інтерфейс до бази законодавства України, що розроблено спільно з апаратом Верховної Ради. У базі більш як 80 000 різних юридичних документів. Автоматичний переклад запитів дає можливість задавати запит на російській або українській мовах. З інформаційних сервісів цікавими є «Карти» і «Розклади потягів». В «Картах» зібрано найбільшу кількість карт по містах і областях України, що є доступними в Інтернеті, а «Розклади» - є найповнішими та найточнішими.
Комунікаційні сервіси - форум, який став найбільшим українським неполітичним форумом. Поштовий сервіс розроблявся значно пізніше за тих, що є зараз на ринку, тому в ньому вдалося обійти відомі недоліки і він вийшов зручним і функціональним. Пошта зараз самий швидкозростаючий сервіс на «Мете».
Пошуковому сервісу доводиться збільшувати потужність одночасно в двох площинах - з одного боку збільшується кількість запитів, з іншої - зростає об'єм індексу. З схожими проблемами працює всього декілька компаній в світі, і тому на вирішення технічних проблем, пов'язаних з швидким зростанням витрачається багато зусиль. Впроваджено і відпрацьовано технологію, що дозволяє швидко масштабувати систему, Мета може без проблем збільшити розмір індексу і обробити число запитів на порядок більше.
З останніх вдосконалень - «перевірка» правопису в запитах і додавання нових форматів документів - doc, pdf, xls, ppt.
«Повільна індексація» - це вже легенда, яка залишилася у минулому. Черги на розміщення в каталог зараз немає, бо технічних потужностей вистачає. Якщо сайт через 4-5 днів після додавання в каталог не потрапив в індекс, це означає, що він є або недоступним, або не піддається індексації. Окрім цього є спеціальний кластер, документи в якому оновлюються двічі у день.
За статистикою користувачі зарубіжних пошукових систем використовують в середньому 1,5 слова в запиті. Наші користувачі більш "багатослівні" -- 2,5 слова на один запит.
В тому випадку, якщо потрібна загальна інформація, що має певне відношення до теми, достатньо одного слова. Напевно серед декількох сотень документів, які видасть Мета буде документ, який відповідає темі пошуку. Проте, де буде цей документ - у першій десятці результатів або десятій десятці - справа випадку.
Щоб отримати підбірку результатів, яка буде точніше відповідати темі запиту і попутно заощадити час на переглядання відповідей пошукової машини краще шукати відразу за декількома словами, що характеризують запит детальніше.
Опис зарубіжних пошукових систем
Більше як 80% всього пошуку в Інтернеті доводитися на 3 основні системи: Google, Yahoo!, MSN.
З невеликої компанії, яка заснована у вересні 1998 року Ларрі Пейджем і Сергієм Бріном, Google перетворилася на найбільший галузевий концерн, що пропонує послуги простого і швидкого пошуку інформації в Інтернеті по більш ніж 8 млрд. мережних адрес, плюс множина інших, не менш цікавих сервісів. За ці роки багато що змінилося, але незмінною і зростаючою залишилася динаміка розвитку Google. Особливо вражає успішне і послідовне зростання компанії на тлі поголовного краху, що зачепів в минулі роки більшість дот-комів.
Нині феноменальний успіх Google пов'язують не лише з вибраною бізнес-моделлю і вдалим напрямом діяльності. Карколомний успіх компанії не був би досягнутий без тонкого підбору співробітників і вмілого керівництва. З серпня 2001 року на посту CEO компанії знаходиться Ерік Шмідт, якій перейшов в Google з Novell і поставив за головну мету збільшення капіталізації за рахунок виходу на нові ринки. Минулі роки підтвердили правильність вибраної стратегії і тепер Google є тим, чим є - близько 5 тисяч співробітників у всьому світі, бренд, що відомий без коментарів в будь-якому куточку земної кулі.
Бренд Google було введено як співзвуччя математичному терміну Googol (гугол), придуманому Мілтоном Сироттой, племінником американського математика Едварда Каснера. Він позначає одиницю з сотнею нулів і чудово ілюструє невичерпні можливості Інтернету, які компанія Google постійно систематизує і організовує, полегшуючи доступ до різних даних.
Спочатку була поставлена мета по організації всієї світової інформації, щоб зробити її максимально доступною і корисною для кожного відвідувача Інтернету. Для цього засновники компанії Леррі Пейдж і Сергій Брін розробили новий алгоритм пошуку. Ідея створення універсального пошуковика і стала запорукою нинішнього успіху компанії. Більш того, в нинішньому своєму втіленні пошуковий движок доступний не лише з головної сторінки Google: можна вести пошук через панель інструментів Google, через Google Deskbar в панелі завдань Windows без відкривання браузера, а також з різних мобільних платформ, включаючи телефони в режимах WAP та І-mode.
Оскільки пошуковик Google є безкоштовним, основний дохід компанії складається з надання рекламодавцям можливості поширювати рекламу, що є релевантною до інформації на даній сторінці. Тисячі рекламодавців використовують програму Google AdWords для просування своїх товарів і послуг за допомогою цілеспрямованих оголошень, тисячі менеджерів сайтів використовують Google AdSense для показу оголошень, що є релевантними до змісту сайтів. Від початку розробники Google відмовилися від типового використання потужностей декількох серверів, продуктивність яких зменшується при пікових навантаженнях, і почали використовувати можливості розподілених у мережі комп'ютерів. Пошуковий движок Google проводить серії одночасних розрахунків тривалістю частки секунди і використовує технологію PageRank для вивчення всієї структури посилань Інтернету та об'єктивного визначення найважливіших сторінок шляхом розрахунку рівняння з більше як 500 змінними і 2 мільярдами термінів. Пошуковик Google аналізує якісний зміст сторінок - шрифти, підрозділи, точне місцеположення кожного слова, плюс зміст сусідніх сторінок для забезпечення максимальної релевантності результатів пошуку. В компанії Google створено технологію пошуку для бездротових пристроїв з моментальним перетворенням HTML у формати для режимів WAP, І-mode, J-SKY і EZWeb. Результатом багаторічного розвитку пошукової системи Google стала поява національних пошукових сервісів: підтримується різномовний інтерфейс і алгоритму пошуку адаптуються до локальних особливостей. Коли пошуковий сервіс Google стартував в Китаї, то, не дивлячись на численні складнощі, пов'язані з своєрідним трактуванням свободи слова китайськими властями (Google.com не доступний китайським користувачам приблизно 10% часу; Google News зовсім не працює, Google Images доступний лише час від часу), сервіс працює і набирає популярність.
Google забезпечує пошук по гіпертекстових документах, що знаходяться в різних мовних зонах - українською, російською, англійською, німецькою і ін. Пошукова система Google має власні піддомени для більшості країн, наприклад, для України - google.com.ua, для Росії - google.ru. Це одна з найбільших пошукових баз в світі.
Переваги
· Використання механізму PageRank, який відображає "важливість" сайту і впливає на видачу результатів пошуку. PageRank схожий на індекс цитування у Яндекса (теж залежить від кількості і якості посилань на ресурс). Але на відміну від Яндекса, вплив PageRank у Google не настільки значний, тому люди в Google знаходять саме те, що і шукають.
· Google шукає не лише гіпертекстові файли (html), але і файли у форматі PDF, DOC, PostScript, Corel Word Perfect і ін.
· Пошукова система Google має можливість пошуку зображень. При цьому у запиті можна вказати бажаний розмір, глибину кольору, формат файлу.
· На відміну від багатьох пошуковиків, роботи Google індексують всі сторінки, а не лише найголовніші.
· Всі сторінки Google кешує (заносить в свою базу), і дозволяє користувачеві переглядати документ у кеші Google, не відкриваючи його в першоджерелі (що зазвичай є набагато швидше).
· Google дозволяє обрати мову інтерфейсу, мовні зони для поуку, кількість повідомлень при видачі результатів та ін.
· Користувачі Microsoft Internet Explorer, Mozilla Firefox і Opera можуть встановити собі програму Google Toolbar, яка створює нову панель інструментів, що дозволяє шукати в Google, не заходивши на сам сайт.
· Рядок пошуку в Google можна використати і як калькулятор. Якщо ввести (48-26)*21, Google видасть правильний результат.
YAHOO
Yahoo було засновано в 1994, і на сьогоднішній день це найстаріший і якнайповніший каталог Інтернет-ресурсів. Ця неймовірно популярна система, що обслуговує мільйони запитів щодня, зародилася як проста колекція закладок, яку поповнювали всього 2 людини - Девід Філо і Джері Янг. Yahoo є найпопулярнішим пошуковим засобом і секрет його успіху Yahoo криється в людях. Над складанням та редагуванням вмісту каталогів Yahoo працюють понад 150 редакторів. Yahoo має базу даних в більш, ніж 1 млн. проіндексованих сайтів. Також, у разі браку власної бази даних, Yahoo використовує базу даних Google (до липня 2000 року Yahoo користувався базою даних Inktomi).
ALTA-VISTA
AltaVista почала надавати свої послуги в грудні 1995 року і на сьогоднішній день є однією з найбільш великих пошукових систем (за кількістю проіндексованих сторінок). Як особливість пошуковика можна зазначити можливість пошуку за ускладненими критеріями відбору. AltaVista пропонує додаткові послуги у вигляді пошуку по каталогах (взятими з Open Directory and LookSmart), а також службу під назвою "Ask AltaVista" ("запитай AltaVista"), результати якої беруться з Ask Jeeves. На даний час AltaVista є власником пошукової системи Raging Search.
MSN
Пошуковик розроблено та запущено компанією Microsoft у 1997 року.
На відміну від інших пошукових систем, раніше у MSN ніколи не було власного павука або каталога. З 1997 року для видачі результатів пошуку використовувалися різні бази даних, такі як: Yahoo!, LookSmart, Altavista, DirectHit, Inktomi і RealNames. Тільки з початку 2005 року MSN запустив бета-версию власного пошукового алгоритму. Користувачі MSN Search можуть здійснювати пошук як по всьому Інтернету, так і по окремих тематичних категоріях, у тому числі і по енциклопедії Microsoft Encarta. Новий движок містить можливість локалізованого пошуку (Near Me) - система здатна автоматично визначати місцезнаходження користувача за IP-адресою його комп'ютера.
Проблеми використання пошукових систем Інтернет
Усі відомі і популярні пошукові системи мають дуже простий інтерфейс, розрахований на недосвідченого користувача, мають безліч настроювань і досить прості у використанні. Але від користувача залежить тільки формулювання запиту, пошук же здійснює убудований механізм пошукової системи. Без правильного планування стратегії пошуку, знайомства з основними принципами роботи інформаційно-пошукових систем важко ефективно використовувати навіть такі сучасні і могутні пошукові служби. При роботі з цими системами варто враховувати ряд факторів.
По-перше, усі пошукові системи в Мережі мають свою спеціалізацію. Наприклад, Lycos і AltaVista містять одні з найбільших масивів посилань і відомі швидкістю додавання нових ресурсів мережі, однак багато ресурсів Інтернет недовговічні і рухливі, і посилання можуть указувати на відсутні ресурси. Infoseek - це найбільш стабільна база даних, де зручно знаходити відомі матеріали, але не слід шукати що-небудь нове, і т.д. у залежності від пошукової системи. У випадку пошуку якої-небудь спеціалізованої інформації користувачу треба відразу настроїтися на тривалу і кропітку працю.
Якщо в звичайній бібліотеці існує зрозуміла класифікація і досвідчений персонал, що розставляє книжки і журнали відповідно до предметного каталогу, загальним для всіх бібліотек, то - у Інтернет такого стандарту нема, і кожна інформаційна служба виробляє свою власну систему класифікації.
Крім того, зовсім очевидно, що Інтернет - це світовий інформаційний ресурс. Сюди поміщається усе, що так чи інакше цікавить людей в усьому світі, тому перш ніж починати що-небудь шукати, варто тверезо оцінити імовірність того, чи може дана інформація взагалі потрапити в мережу і де найбільш логічне для її місце.
По-друге, варто розуміти, що пошук здійснюється не природною мовою і не по всьому тексту документа. Звичайно документ представлений набором ключових слів - пошуковим образом документа (ПОД), а користувач здійснює пошук не в наборі документів, а в наборі їхніх пошукових образів. Крім того, для кожної пошукової системи характерний свій механізм створення ПОД. Природно, що це впливає на результати пошуку.
По-третє, самі запити і їхня інтерпретація в інформаційних системах Інтернет реалізовані по-різному, хоча поза залежністю від типу інформаційно-пошукової мови багато систем містять можливість сформулювати простий запит і запит з урахуванням специфіки пошукового апарата системи.
Простий запит - це фраза природною мовою без загальних слів, союзів і приводів. Складний запит - це запит, що враховує специфіку системи і дозволяє користувачу варіювати різні параметри пошуку. Після завершення обробки запиту користувачу видається список посилань на документи, де вже можна використовувати гіпертекстові посилання для перегляду. Ці посилання можуть указувати як на Web-сторінки, так і на одиниці збереження інших інформаційних ресурсів Інтернет.
По-четверте, у даний час для управління інформацією Web у пошукових вузлах застосовуються два різних механізми -- покажчики і каталоги, і різні пошукові системи використовують у своїй роботі різні механізми.
Покажчики Web являють собою громіздкі бази даних, формовані комп'ютером в автоматичному режимі й утримуючі інформацію про мільйони сторінок Web. Коли користувач уводить ключові слова чи фрази, пошукова система шукає ці терміни в існуючій виданий момент базі даних і видає посилання на усі відомі їй сторінки із шуканими термінами. Покажчики Web будуються так званими краулерами Web -- програмами, що переглядають і індексують вміст HTML-сторінок, виявляють гіпертекстові зв'язки, що містяться в них, і читають відповідні сторінки. Багато сотень таких програм із заданою періодичністю переглядають весь доступний вміст Інтернет.
Каталоги Web -- це зв'язані між собою гіпертекстовими посиланнями списки вузлів Web, упорядковані по тематичних категоріях.
Каталоги Web створюються людьми, а не комп'ютерами і часто містять рекомендації чи анотації до вузлів. Вони охоплюють значно менше тим, чим зібрані комп'ютером покажчики Web, але незмінно краще сплановані.
Таким чином, кожна система має велику кількість унікальних характеристик, своїх особливостей, що накладають відбиток на результат пошуку в Мережі. Більш того, багато пошукових систем відрізняються друг від друга досить значно, оскільки побудовані на різних методах пошуку й індексування інформаційних ресурсів. Але проте цілком реально розібратися в тім, на: якому принципі заснована робота більшості пошукових систем Мережі, як у загальному випадку здійснюється пошук документальних ресурсів у Інтернет.
Хотілося б сказати, що існуючі на даний момент пошукові системи - це досить могутні і здебільшого досить гнучкі інструменти пошуку інформації. Якщо точно знати, що ж вам дійсно потрібно в Мережі і відповідно до цим уміло скласти запит, практично всі ІПС видадуть на ваш запит достатнє (і навіть надлишкове) кількість посилань на ресурси Інтернет, у яких не так вже і складно знайти потрібну вам інформацію.
Але не можна не сказати, що при єдності основних принципів пошуку всі нині існуючі пошукові системи мають ряд відмінних риc. Знання цих особливостей буває не тільки корисно, але іноді і необхідно при пошуку якої-небудь рідкої чи специфічної інформації. Ці особливості не вносять кардинальних змін у механізм пошуку, але кожна пошукова система має свій алгоритм і свої особливості роботи, що в остаточному підсумку впливають на результати пошуку. Користувач повинний чітко розуміти, який ІПС краще скористатися в кожнім конкретному випадку.
Підвищення ефективності пошуку інформаційних ресурсів Інтернету
Як краще працювати з пошуковими системами Інтернету? Передусім треба пам'ятати, що складання запитів на пошук інформації - це свого роду мистецтво. Ідеальний запит видасть користувачу посилання тільки на ті сторінки, що йому потрібні. Просто грамотний запит може видати користувачеві кілька десятків сторінок, пошук серед яких виявиться не таким уже й складним.
Користувачу слід мати на увазі, що жодна пошукова система не в стані повністю індексувати всі сторінки і документи на всіх серверах Інтернету. Кожний пошуковий сервер проводить відбір і індексування сторінок за своїми власними правилами.
В ефективному пошуку інформаційних ресурсів Інтернету допомагають декілька правил.
1. Грамотне використання можливостей одного пошукового сервера може бути ефективніше, ніж звернення з тим самим запитом до великої кількості серверів.
Коли користувач вперше потрапляє на сторінки незнайомого пошукового сервера, слід в першу чергу прочитати його опис і правила користування, а також вивчити засоби і можливості пошуку. Однак не слід захоплюватися вивченням пошукових серверів; після деякої практики з'являються 2-3 улюблені сервери, що найповніше індексують сферу в Інтернеті, яка цікавить користувача.
2. У запиті слід використовувати ті слова, що точніше за все характеризують тему, яка цікавить користувача.
Вибір слів може грунтуватися на двох різних підходах:
- можна почати із загального запиту і поступово його конкретизувати, спостерігаючи за зміною результатів пошуку;
- можна почати з конкретного запиту і поступово його поширювати, відштовхуючись від найбільш важливих і специфічних слів.
3. Для більшості пошукових серверів має значення послідовність слів у запиті, тому найбільш важливі і характерні терміни треба розміщувати на початку запиту і додавати до них менш значущі терміни.
4. Фрази і словосполучення слід брати в лапки, оскільки в противному разі вони будуть сприйняті пошуковим сервером просто як набір ключових слів.
5. У запиті можна зазначати одне або кілька власних імен.
6. Рекомендується вживати синоніми - їх використання дозволяє не тільки поширити діапазон пошуку, а й надає більше ваги власне смисловій частині запиту.
7. Не рекомендується користуватися поширеними словами типу "комп'ютер", "інформація", "дані" тощо.
8. Багато пошукових систем припускають можливість використання в запитах логічних операторів "І" (AND), "або" (OR), "не" (NOT). Їх грамотне використання дозволяє зробити пошук надзвичайно точним і направити його саме туди, куди потрібно.
9. Якщо серед перших 20-30 посилань, отриманих від пошукового сервера, немає потрібного посилання, слід подумати про те, щоб радикально змінити набір ключових слів або скористатися іншим сервером.
10. Слід пам'ятати, що WWW-сторінка, на яку користувач потрапляє при першому підключенні до пошукової системи, найчастіше являє собою спрощений бланк запиту на пошук інформації. Щоб отримати доступ до найбільш потужних засобів опису, треба перейти на сторінку ускладненого пошуку (Advanced Search).
Практична частина
У цій частині розглядатимемо практичні поради застосування пошукових операторів, які можуть наштовхнути викладачів на нові ідеї в роботі з Google. Розглянемо на практиці особливості пошуку інформації різноманітних напрямків, які допоможуть ефективно орієнтуватися в всесвітній павутині
1. Часові рамки
Обмеження щодо дат є, мабуть, найефективнішим способом швидко знаходити першоджерела. Адже, задавши вузькі часові рамки, ключові слова можна залишити більш загальними.
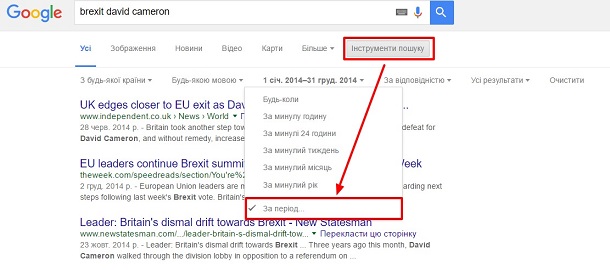
Задача. Треба простежити позицію прем'єр-міністра Великобританії Девіда Кемерона стосовно виходу з ЄС у 2014 році.
Вирішення. Замість пошукового запиту brexit david cameron 2014, краще ввестиdavid cameron brexit та обмежити в часі.
Порада. Замість того щоб вводити в полях «З» і «До» «1 січня 2014» і «31 грудня 2014» відповідно, можна просто зазначити рік без місяця й дати. Google автоматично їх переводить у початок та кінець року, якщо немає уточнень.
2. Пошук за сайтами, країнами та регіонами (site:)
Незамінний оператор для журналістів – site:.
По-перше, можна вказувати конкретний сайт, не використовуючи пошукові системи власне самого сайту (хоча бувають сайти, на яких пошуковик не може нічого знайти, але це рідкість).
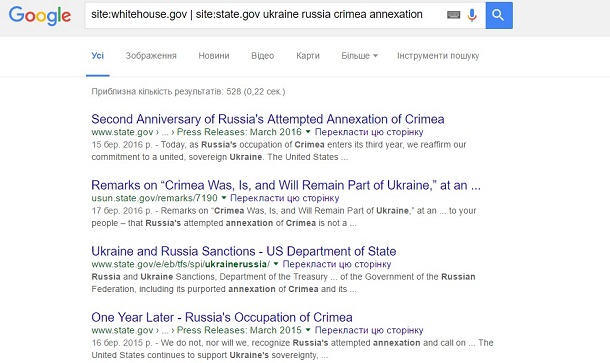
Задача. Знайти інформацію про позицію влади США стосовно анексії Криму Росією.
Вирішення. Як варіант, можна обмежити сайтами Білого дому та держдепартаменту США: site:whitehouse.gov | site:state.gov ukraine russia crimea annexation.
По-друге, важливо, що шукати можна не тільки за повною адресою сайту, як site:rada.gov.ua, а й за доменами для регіонального звуження. Наприклад, site:ru шукатиме тільки на російських сайтах. Запит site:gov.ua дає змогу шукати інформацію на сайтах українських органів влади. Аналогічно можна шукати за регіональними сайтами, як site:kiev.ua або site:kherson.ua. Або за сайтами так званих «ДНР» та «ЛНР», які часто користуються доменом su (Soviet Union), – site:su.
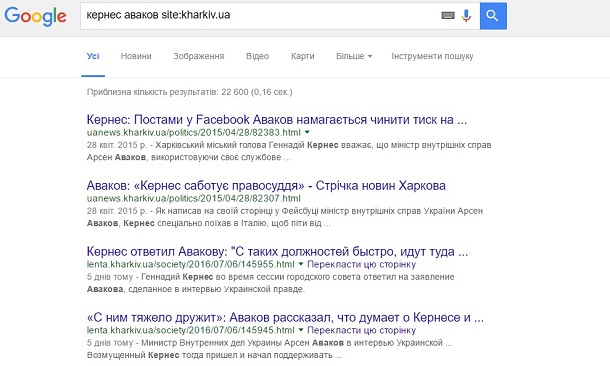
Задача. Що писали харківські онлайн-ЗМІ про взаємини між Арсеном Аваковим та Геннадієм Кернесом?
Вирішення. Увести кернес аваков site:kharkiv.ua
Так само можна шукати за піддоменами (site:blogs.korrespondent.net – пошук у блогах видання «Кореспондент») чи за глибшими доменами (site:www.pravda.com.ua/graphs/ - пошук тільки за статтями з інфографікою на «Українській правді»).
3. Знайти документ або презентацію (filetype:)
Іще один надзвичайно корисний оператор, який дає змогу відсіяти сторінки з малозначущою інформацією.
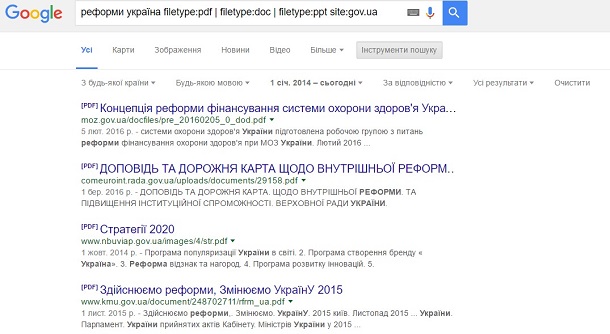
Задача. Дізнатися офіційні повідомлення про реформи в Україні. Часто державні сайти публікують інформацію у форматах Adobe Acrobat Reader, Microsoft Word, Microsoft Excel або ж як презентацію в Microsoft Power Point.
Вирішення. Одним із варіантів такого пошуку є запит реформи україна filetype:pdf | filetype:doc | filetype:ppt | filetype:xls site:gov.ua. На додачу пошук можна обмежити 2014–2016 роками.
Так само можна шукати музику (mp3), фільми (avi), архівні файли (zip) чи будь-який інший формат.
4. Тільки найважливіше (inurl: та intitle:)
Заголовки текстів мають неабияку цінність, бо зазвичай у них закладають ключові слова з тематики матеріалу. Відповідно, знаючи або здогадуючись про них, можна значно звузити результати за допомогою операторів intitle: та allintitle: Перший шукає тільки одне слово після нього або вислів у лапках, другий шукатиме всі слова в запиті.
Задача. Дослідити скандал довкола листування кандидатки в президенти США Гіларі Клінтон і допиту ФБР.
Варіанти вирішення
- intitle:клінтон фбр скандал – насамперед треба шукати заголовки зі словом «Клінтон»;
- allintitle:клінтон фбр скандал – на відміну від попереднього пошуку, результатів буде в 10 разів менше, адже Google покаже всі статті з такими словами в заголовку;
- intitle:клінтон intitle:фбр intitle:скандал – аналог попереднього оператора allintitle.
Кожна сторінка в інтернеті має свій унікальний шлях - url. Зазвичай їх автоматично формують сайти на основі заголовку матеріалу або ж уносять вручну редактори. Оператор inurl: якраз і каже шукати тільки серед цих слів. Тому inurl фактично подібний за пошуковими результатами до intitle. Для українського та російського сегментів інтернету його недоліком є те, що url-назви часто мають різну форму: або сформовані кирилицею, або перекладом із латинськими літерами, або простою транслітерацією, або ж узагалі вони є числом. Але завжди можна скористатися оператором OR, надавши різні варіанти.
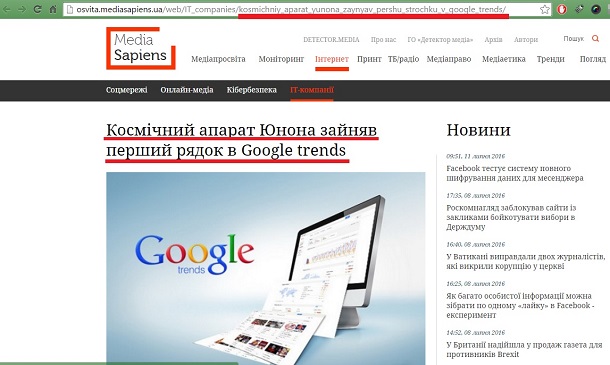
Задача. Дізнатися, що писали на сайті Media Sapiens про друковане видання «Вести».
Вирішення. Запит site:osvita.mediasapiens.ua inurl:*vesti
Зверніть увагу на зірочку перед vesti. Сайт Media Sapiens під час генерування url-адреси заповнює пробіли між словами знаком «_» (нижніми підкресленнями). Тому адреса сприймається як одне суцільне слово. Знак зірочки в цьому разі каже шукати цю послідовність символів (vesti) також усередині слова або url-адреси. Але не переймайтеся, сайти зазвичай використовують замість нижнього підкреслювання «-» (дефіс), який для Google є аналогом пробілу.
5. Геть непотрібне (-)
Знак «мінус» перед словом чи оператором каже Google пропускати відповідні сторінки.
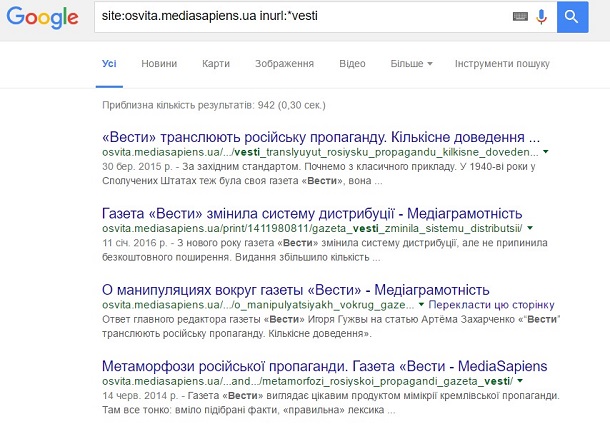
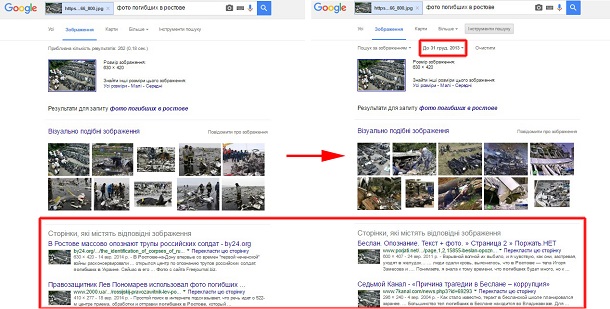
Задача. Треба дізнатися про музичне минуле вбитого на Донбасі українського оперного співака Василя Сліпака. Якщо ввести просто його ім'я та прізвище, то більшість новин будуть пов'язаними з бойовими діями на сході України та його смертю, бо саме тоді про нього масово заговорили видання. Звісно, можна обмежити пошук часовими рамками (до 2014 року). Однак Google інколи підхоплює під час індексування сторінок стрічки новин та коментарі, створені в інший час. А це забруднює результати пошуку. Наприклад, за запитом василь сліпак (з обмеженням часу до 2014 року) підтягнулася новина про Василя Вірастюка 2008 року.
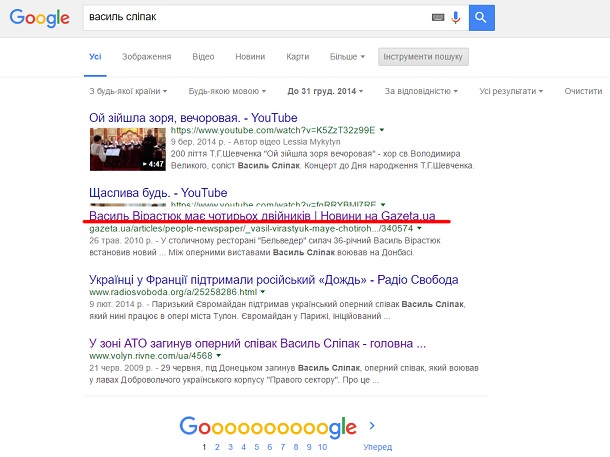
Чому так сталося? Ось новина на сайті Gazeta.ua. У нижньому лівому кутку є блок із фото з актуальними подіями, де була історія про Василя Сліпака, яка й індексувалася пошуковими роботами.
Вирішення. Можна ввести запит, на зразок цього: "василь сліпак" -загинув -воював -"правий сектор" -ато -погиб. На додачу обмежити в часі до кінця 2013 року. Хоча це не позбавить результат від матеріалів про його смерть, пошукова стрічка буде чистішою.
6. Додатковий фільтр для пошуку реверсних фото.
Оператор «-» (мінус) може бути особливо корисним під час реверсного пошуку оригінальних зображень. Часто фотографії з новинових ресурсів активно поширюються в соціальних мережах, що може ускладнювати пошук оригінального зображення. У такому разі в полі Google під час пошуку зображення можна додати комбінацію: -site:vk.com. Або ж, навпаки, можна обмежити пошук зображення тільки в соціальній мережі (наприклад site:facebook.com) або тільки на російських сайтах (site:ru). Майте на увазі, пошук за зображеннями працює зазвичай тільки з одним оператором. Якщо ви спробуєте до -site:vk.com іще додати -site:facebook.com, то результати будуть порожніми.
Однак дуже корисним є обмеження в часі. Особливо коли йдеться про фотографії, які нібито мають стосунок до війни в Україні. Щоб швидко перевірити їхню оригінальність, можна попросити Google показати тільки зображення, опубліковані до 2014 року (порівняйте з результатами без часового обмеження).
7. Пошук цитат («»)
Лапки кажуть Google шукати слова саме в такій послідовності та в такій формі. Це добре спрацьовує для перевірки цитат.
Задача. Треба знайти більше про контекст ужитої цитати Володимира Путіна «российских войск на Украине нет».
Вирішення. Значно ефективнішим буде ввести фразу в лапках «российских войск на Украине нет» (19 тис. результатів), ніж без них – 2,6 млн.
8.AND/OR
Оператор AND змусить пошуковик знайти сторінки з обома заданими словами. Використовують його досить рідко, адже Google автоматично сприймає пробіли між словами як зв'язок AND.
Натомість оператор OR дає Google вибір, що шукати.
Задача. Дізнатися про бої братів Кличків 2010 року.
Вирішення. Можна ввести запит 2010 бій кличко віталій OR володимир. Запит без OR - 2010 бій кличко віталій володимир - буде трохи іншим, адже спочатку йтимуть результати, де про обох братів згадано в статті.
Порада. Замість слова OR можна вводити вертикальну риску - |.
9. Коли забули слово або число (*,…)
Google має кілька операторів, які допоможуть вам знайти потрібну інформацію, навіть якщо ви забули слово або число. Хоча на практиці майже ніколи не випадало ними користуватися, можуть бути випадки, коли вони будуть потрібні.
Оператор * корисний у разі, якщо вам відомий порядок слів у цитаті, але ви не пам'ятаєте слово або одне слово може змінюватися. Наприклад, запит «як тебе не любити * мій» покаже різні варіанти народної творчості за київським аналогом.
Також у Google є трохи дивний на перший погляд оператор «…». Його функція – дати вам змогу шукати різні числові варіації. Наприклад, за допомогою ваз 2101…2109 можна вивести статті про марки автомобіля «Жигулі» з 2101 до 2109. На жаль, цей оператор не працює з пошуком фотографій.
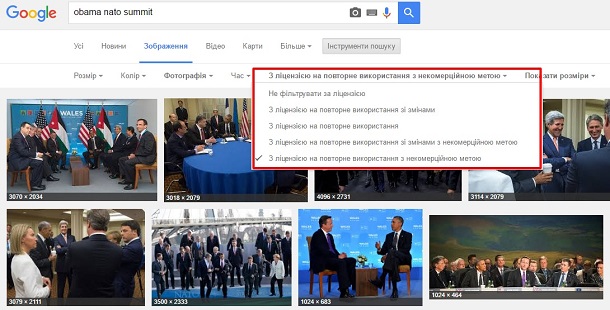
10. Фото без порушення авторських прав
Google дає змогу шукати зображення, які можна впевнено змінювати та публікувати на своїх сайтах. Докладніше про це – на сайті Google. Ця опція доступна в полі пошуку зображень. Наприклад, потрібна фотографія Барака Обами із самітів НАТО.
Висновки
В кінці двадцятого століття цивілізований світ включився у фазу динамічного розвитку нових технологій нерозривно пов'язаних з комп'ютерними технологіями. Таким чином завершилась стадія персоналізації комп'ютерів і почалось лиш удосконалення їх можливостей та надання більшої зручності.
Якщо Вам необхідно відшукати деяку інформацію у мережі Інтернет, скористайтеся можливостями вище наведених служб, спеціально призначених для цілей пошуку даних різноманітними засобами.
Список використаної літератури
- Вікіпедія - http://ua.wikipedia.org/wiki.
- Козлакова Г.О. Комп'ютеризовані технології обробки ділової інформації: Навчальний посібник/ За ред. В.К. Костюка. – Київ - Рівне: РДТУ, 2001. – 233 с.
- Кадемія М.Ю. Формування професійних знань учнів профтехучилищ засобами мережних комунікацій: дис... д-ра пед. наук: 13.00.04. — К., 2004. - 255 с.
- Муртазин Э.В. Internet. Самоучитель. – М.: ДМК Пресс, 2002. – 432 с.
- Интернет. Энциклопедия. / Сост. Ю. Солоницын, В. Холмогоров. – 3-е изд. – Спб.: Питер, 2003. – 592 с.
- Bizon N., Raducu R. Internet and training needs evaluation in “Muntenia”Training center // Матеріали ІІІ Міжнар. конф. "Інтернет – Освіта – Наука – 2002". - Том 1. - Вінниця: УНІВЕРСУМ-Вінниця. - 2002. – С. 46-50.
- Петришин Л.Б., Малько О.Г. Практика застосування новітніх інфотехнологій як засади вдосконалення якості навчального процесу // Матеріали ІІІ Міжнар. конф. "Інтернет – освіта – наука – 2002". – Том. 1. - Вінниця: УНІВЕРСУМ-Вінниця. – 2002. – С. 16-17.
1


про публікацію авторської розробки
Додати розробку