Урок виробничого навчання: "Налаштування інтерфейсу програми оптичного розпізнавання тексту. Сканування текстових документів, малюнків. Розпізнавати текст."

План уроку виробничого навчання
Тема програми : Виконання робіт з обробки інформації
Тема уроку: Налаштування інтерфейсу програми оптичного розпізнавання тексту. Сканування текстових документів, малюнків. Розпізнавати текст.
Мета уроку:
- навчальна: навчити сканувати та розпізнавати текст та малюнки за допомогою програми ABBYY Finereader.
- розвиваюча: розвивати пам'ять , увагу, технологічне мислення, професіоналізм;
- виховна: виховувати дисциплінованість, працелюбність, чесність, порядність.
Тип уроку: урок засвоєння нових знань та умінь.
Методи проведення уроку: розповідь-пояснення, самостійна робота.
Матеріально-технічне забезпечення уроку: персональні комп’ютери, програмне забезпечення: програма Microsoft Word, ОС Windows 7, програма ABBYY Finereader.
Дидактичне забезпечення уроку:
- інструкція для роботи з програмою ABBYY Finereader (https://help.abbyy.com/assets/uk-ua/finereader/12/Users_Guide.pdf ),
- матеріали для самостійної роботи.
Хід уроку виробничого навчання
І. Організаційна частина
1) Перевірка стану обладнання.
2) Перевірка наявності учнів на уроці.
3) Записи в журналі та зошиті допуску до роботи згідно правил т/б.
ІІ. Вступний інструктаж
- Повідомлення теми програми і теми уроку.
- Цільова установка уроку.
- Викладення нового матеріал (додаток 1).
- Закріплення нового матеріалу.
- Пояснення та показ найбільш раціональних прийомів і послідовність виконання завдань
- Пояснення правил охорони праці, техніки безпеки та електробезпеки (додаток 3).
- Пояснення характеру та призначення наступної роботи, порядку виконання самостійної роботи.
- Розподіл учнів за робочими місцями, дозвіл приступити до виконання роботи.
- Самостійна робота (додаток 2).
Ознайомитися із роздатковим матеріалом для самостійної роботи ( додаток 2).
ІІІ. Поточний інструктаж.
Цільові обходи:
- простежити за своєчасним початком роботи учнів та організацією робочих місць;
- перевірити правильність виконання трудових прийомів;
- простежити за дотриманням правил безпеки праці;
- звернути увагу на самостійне виконання робіт учнями;
- конкретно з кожним учнем обговорити виконання даної роботи
- надати допомогу учням, яким важко працювати в даній програмі.
- Заключний інструктаж:
-
Підведення підсумків за урок:
- дотримання правил з охорони праці;
- організація робочих місць;
- дотримання трудової та виробничої дисципліни;
- досягнення мети уроку.
-
Аналіз робіт, виконаних учнями:
- відзначити учнів, які найкраще працювали продовж уроку;
- аналіз допущених помилок;
- оцінювання навчальних досягнень.
- Домашнє завдання:
Майстер виробничого навчання: Романович О. М.
Додаток 1
Теоретичні відомості
Сам процес сканування дуже простий, хоча його результати можуть істотно розрізнятися і залежать від якості оригіналу (сканованого документа). Сторінка, що містить текст, поміщається на стіл для оригіналів і запускається програма розпізнавання тексту. У цій програмі (у даній роботі це FineReader) задаються параметри сканування і тип текстового файлу. Після завершення сканування ми одержуємо текстовий файл, який можна відкрити і редагувати в Word або будь-якій іншій аналогічній програмі.
У минулому OCR-сканери могли розпізнавати тільки певні шрифти, які називалися OCR-шрифтами, а документи, призначені для сканування, також друкувалися цими шрифтами. Для генерації OCR-шрифтів використовувалися спеціальні пишучі машинки.
Крім того, для оригіналів необхідно було використовувати спеціальний папір з дуже високим ступенем білизни (в цьому випадку сканеру простіше відділити чорний шрифт від фону). Ці пристрої дійсно були достатньо капризними, але, оскільки OCR-програми прогресували достатньо швидко, з часом вони навчилися розпізнавати практично будь-який надрукований шрифт, за винятком шрифтів, що імітують рукописний текст.
Для прикладу OCR-системи я вибрав програму ABBYY FineReader 7.0. Багато користувачів комп'ютерів що мають сканер застосовують для сканування і розпізнавання тексту саме цю програму.
Сканер — це «пристрій, що використовується для аналізу початкового зображення або тексту, його оцифровки і збереження з метою подальшої обробки і висновку».
Коротка історія сканерів
Сканери з'явилися достатньо давно, і прийшли на робочі столи домашніх і професійних користувачів з поліграфії. Перші сканери використовувалися для підготовки цветоделенних зображень для чотирьохбарвистого друку і були частиною допечатних комплексів, які, в найдешевшому виконанні, коштували сотні тисяч доларів. Це було в 1970-е роки, коли все було велике, починаючи з автомобілів і закінчуючи допечатними системами. У той час не було потреби в настільних сканерах, оскільки ще не існувало т.зв. «настільних видавничих систем». Поява цих систем стала революцією у виданні друкарської продукції і привела до передачі багатьох технологій широким шарам користувачів, хоча вони для них ніколи не призначалися. У той час сканери практично не використовувалися для оцифровки зображень, оскільки в цьому не було необхідності: зображення готувалися до друку за допомогою фотографічних процесів.
У середині 1980-их років зійшлися разом декілька Технологій. У комп'ютерах Apple Macintosh почала використовуватися відеосистема, що реалізовує концедцшоу оптимістично названу WYSIWYG («what-you-see-is-what-you-get» — що бачите, то і одержуєте). З'явилася мова Postscript компанії Adobe Systems, яка дозволила вивідним пристроям незалежно від їх апаратної реалізації (включаючи лазерні принтери) відтворювати елементи верстки смуги (особливо це відноситься до шрифтів). І, нарешті, була випущена програма PageMaker компанії Aldus, яка була першим повноцінним додатком для створення макетів сторінок на персональному комп'ютері.
Ці події, а також інші, трохи менш помітні досягнення, дали можливість масовому користувачу самостійно готувати публікації до друку. Тепер будь-який користувач комп'ютера міг створити журнал, інформаційний бюлетень і навіть книгу, і цим комп'ютером не обов'язково повинен був бути Macintosh. На платформі PC (у той час ще не було Widows, а тільки DOS) з'явилася програма Xerox Ventura Publisher (сьогодні це Corel Ventura). Це був повноцінний видавничий інструмент, що містить безліч новацій, що випередили свій час, які, зрештою, були включені до складу настільних видавничих систем QuarkXPress і PageMaker, що стали в подальшому популярнішими.
Отже, перші сканери були великими, незграбними і дуже дорогими. Сканування зображень і доведення їх до такого вигляду, щоб вони підходили для друку, було зовсім не домашнім заняттям; це був сервіс, що надається спеціалізованими сервісними бюро. Поступово стали з'являтися невеликі планшетні сканери, які могли сканувати тільки чорно-білі зображення. Вони не давали високої якості, і скануючі зображення вставлялися в макети тільки з метою фіксації їх розмірів і місця розташування!
Такий стан тривав до середини 1990-х років, коли стали з'являтися перші кольорові планшетні сканери, що вже дозволяють говорити про підготовку зображень для друку. Ці пристрої були ще дорогі (більше $1000), але якість і ціни дуже швидко поліпшувалися. До кінця 1990-х років пристойний планшетний сканер можна було придбати за $500. Зараз же хороший сканер стоїть $200, а непоганий — навіть менше $100.
Все це вивело сканери на рівень масового споживача. Пристрої стали настільки дешевими у виробництві, що тепер їх іноді використовують як подарунок при покупці домашнього комп'ютера: купуєте новий PC Pentium і одержуєте «безкоштовний» сканер. Тепер це всього лише один з видів домашньої електронної техніки,. Все більше і більше людей користуються Web і e-mail, і завжди знайдеться достатня кількість старих фотографій, які можна оцифрувати і послати по електронній пошті або розмістити на своїй домашній Web-сторінці або Web-вузлі.
Сканування
Сканування починається з освітлення поверхні оригіналу (або світло проходить через оригінал, якщо останній є слайдом). Потім світло відображається дзеркалами і потрапляє в об'єктив, який фокусує зображення на світлочутливому детекторі. У сканерах різних виготівників застосовуються різні типи ламп.
Системи оптичного розпізнавання символів (Optical Character Recogmtion - OCR) призначені для автоматичного введення друкованих документів у комп'ютер.
FmeReader - омніфонтова система оптичного розпізнавання текстів. Це означає, що вона дозволяє розпізнавати тексти, набрані практично будь-якими шрифтами, без попереднього навчання. Особливістю програми FmeReader є висока точність розпізнавання і мала чутливість до дефектів друку, що досягається завдяки застосуванню технології "цілісного цілеспрямованого адаптивного розпізнавання".
Процес уведення документа в комп'ютер можна розділити на два етапи:
- Сканування. На першому етапі сканер відіграє роль "ока" Вашого комп'ютера: "переглядає" зображення і передає його комп'ютеру. При цьому отримане зображення є не чим іншим, як набором чорних, білих чи кольорових крапок, картинкою, що неможливо відредагувати в жодному текстовому редакторі.
- Розпізнавання. Обробка зображення OCR-системою.
Обробка зображення системою FmeReader містить у собі аналіз графічного зображення, переданого сканером, і розпізнавання кожного символу. Процеси аналізу макета сторінки (визначення областей розпізнавання, таблиць, картинок, виділення в тексті рядків і окремих символів) і розпізнавання зображення тісно зв'язані між собою: алгоритм пошуку блоків використовує інформацію про розпізнаний текст для більш точного аналізу сторінки.
Як уже згадувалося, розпізнавання зображення здійснюється на основі технології "цілісного цілеспрямованого адаптивного розпізнавання".
- Цілісність - об'єкт описується як ціле за допомогою значимих елементів і відносин між ними.
- Цілеспрямованість - розпізнавання будується як процес висування і цілеспрямованої перевірки гіпотез.
- Адаптивність - здатність OCR-системи до самонавчання.
Відповідно цим трьом принципам система спочатку висуває гіпотезу про об'єкт розпізнавання (символі, частині символу чи декількох склеєних символах), а потім підтверджує чи спростовує її, намагаючись послідовно знайти всі структурні елементи і пов’язуючи їх відносини. У кожному структурному елементі виділяються частини, значимі для людського сприйняття: відрізки, дуги, кільця і крапки. Наслідуючи принцип адаптивності,програма самостійно "настроюється", використовуючи позитивний досвід, отриманий на перших упевнено розпізнаних символах. Цілеспрямований пошук і облік контексту дозволяють розпізнавати розірвані і перекручені зображення, роблячи систему стійкою до можливих дефектів листа.
У результаті роботи у вікні FrneReader з'явиться розпізнаний текст, який можна відредагувати і зберегти в найбільш зручному форматі.
FineReader 6.0 окрім 177 звичайних мов, розуміє також основні мови програмування і прості хімічні формули, причому вміє розпізнавати різномовний текст. Має функцію навчання. Успішно інтегрується з Microsoft Office (не тільки з Word, але й з Excel). Крім того, відсканований файл можна відразу відправити електронним листом або завантажити в браузер у вигляді веб-сторінки. FrneReader дозволяє відкривати і розпізнавати PDF-файли. PDF - один з найбільш популярних форматів збереження документів в !nternet, в архівах і т.д. Відкривши PDF-файл у FrneReader, Ви можете розпізнати його, відредагувати і зберегти або в PDF, або в будь-якому іншому підтримуваному форматі збереження.
Головне вікно програми має наступний вигляд
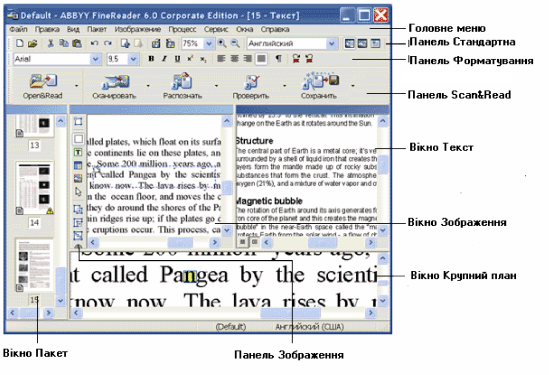
Угорі Головного вікна FrneReader знаходиться меню системи, під ним - інструментальні панелі. У програмі їх чотири: Стандартна, Форматування, Зображення і Scan&Read.
Відсканований документ існує в програмі в трьох формах:
• у вигляді значка або ескізу - на лівій панелі (вона називається Пакет);
- у вигляді зображення - на середній панелі (Зображення);
- у вигляді розпізнаного тексту - справа (панель Текст).
На самій нижній горизонтальній панелі міститься збільшене зображення того участка тексту, який переглядається (панель Крупний план).
Вікна Зображення, Крупний план і Текст пов'язані між собою: при подвійному кліку на зображенні у вікні Зображення курсор у вікнах Крупний план і Текст (при наявності розпізнаного тексту) переміститься на ту ж позицію, що й у вікні Зображення.
Основна робота програми FmeReader 6.0 ведеться в пакетному режимі, оскільки кожне відскановане зображення записується як окрема сторінка пакету. У пакеті зберігаються як вихідні зображення, так і відповідний їм розпізнаний текст. Більшість установок FmeReader зберігаються на пакет (опції сканування, розпізнавання, збереження, а також створені в процесі роботи користувальницькі еталони, мови і групи мов).
Процес обробки документу програмою FmeReader 6.0 складається з наступних етапів:
- Сканування документу.
- Розпізнавання документу.
- Перевірка орфографії.
- Збереження документу.
Сканування. Кожна модель сканера має свою програму, свої настройки і свої можливості. Але всі такі програми роблять швидке попереднє сканування (Previev), після якого можна:
- виділити мишею область сканування;
- обрати режим сканування - кольоровий файл, чорно-білий, з відтінками сірого і т.д.;
- виставити параметри яскравості, контрасту та ін. або обрати автоматичне визначення цих параметрів;
- запустити основне сканування (Scan).
Щоб запустити процес сканування слід натиснути кнопку „Сканировать”

|
Открыть изображение... |
Ctrl+0 |
|
Сканировать изображение... |
Ctrl+K |
|
Сканировать несколько страниц.. |
Ctrl+Shift+K |
Якщо необхідно відсканувати декілька сторінок, слід в локальному меню обрати пункт „Сканировать несколько страниц”.
Розпізнавання. Перед початком розпізнавання необхідно перевірити опцію „язык распознавания” а потім натиснути кнопку „Распознать”:
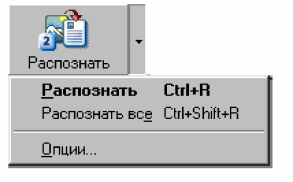
Якщо на попередньому етапі було відскановано декілька сторінок, в локальному меню слід обрати пункт „Распознать все”.
FmeReader не просто розпізнає текст, але й відтворює розмір та накреслення шрифту - підкреслений, напівжирний, курсивний та їх поєднання. Відтворюється й оформлення абзаців - вирівнювання, відступи, маркіровані списки. Те, що FmeReader не може розпізнати як текст, він вважає малюнком і вставляє в документ у вигляді графічного фрагменту.
Після завершення розпізнавання результат з'являється у вікні Текст. Вікно Текст - це вбудований редактор програми FmeReader; у ньому можна перевірити результати розпізнавання і відредагувати розпізнаний текст.
Перевірка орфографії. Одна з можливостей текстового редактора FmeReader - це вбудована перевірка орфографії.
Система убудованої перевірки орфографії дозволяє:
- знаходити непевно розпізнані слова (слова, у яких є непевно розпізнані символи);
- знаходити орфографічні помилки (неправильно написані слова);
- додавати невідомі системі FmeReader слова в словник для того, щоб вони розпізнавалися впевнено.
Непевно розпізнані символи і слова, яких немає в словнику, виділяються різними кольорами. За замовчуванням для виділення непевно розпізнаних символів використовується блакитний, для несловникових слів - рожевий.
Щоб перевірити результати розпізнавання слід натиснути кнопку „Проверить” на панелі інструментів Scan&Read, в результаті відкриється діалог „Перевірка”
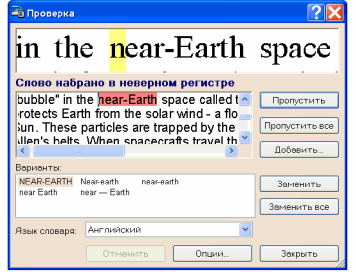
Діалогове вікно “Перевірка”
У діалозі Перевірка три вікна. Верхнє вікно - аналог вікна "Крупний план" програми FmeReader, у ньому показане зображення слова з можливою помилкою. Середнє вікно показує саме слово з можливою помилкою, у рядку над цим вікном виводиться назва типу помилки. У нижньуом вікні, Варіанти, пропонуються варіанти заміни даного слова (якщо такі існують). Для варіантів використовується словник, зазначений у полі Мова словника. Можна використовувати будь-як словник із запропонованого списку.
Також для переміщення по непевно розпізнаних словах можна використовувати гарячі клавіші: F4 (SHIFT F4).
Збереження результату. Для збереження результату слід скористатись кнопкою „Сохранить” на якій є випадаючий список (рис. ). FmeReader може просто зберігати файли або передавати їх безпосередньо в буфер обміну або одну з перерахованих програм.
Команда „Сохранить текст в файл” дозволить записати текст на диск в одному з відомих FineReader’y форматів.
У стрічці Опции можна задати:
- щоб кожна сторінка була записана в окремий файл;
- щоб кожна сторінка була записана в окремий файл, ім’я якого співпадає з іменем вхідного файлу;
- щоб всі сторінки записались в один файл;
- щоб все записалось в один файл, але кожна сторінка - з нового листка.
При прямій передачі файлів у текстовий або табличний редактор ніяких додаткових параметрів вказувати не потрібно.
Зауваження. В процесі розпізнавання автоматично розмічає скановане зображення блоками трьох видів - текстовими (виділяються рамкою зеленого кольору), табличними (сині) та графічні (червоні). Відповідно програма і відноситься до кожного такого блока: текст розпізнає, картинку не розпізнає - просто вставляє в документ, а в таблиці спочатку шукає стрічки і стовпці, а потім розпізнає - по коміркам.
Інколи в результаті автоматичного аналізу програма неправильно розмічає сторінку блоками. Тоді необхідно виділяти та редагувати блоки вручну. Границі блоків можна рухати мишею за верхні і бокові сторони та за вузли. Коли нові границі блоку повністю перекривають якийсь зі старих блоків, той за непотрібністю зникає.
Також для виділення та редагування блоків вручну можливе використання панелі інструментів Зображення.
Панель Зображення містить кнопки, що дозволяють робити аналіз макета сторінки (наприклад, створити і відредагувати блоки), а також кнопки, що дозволяють збільшити/зменшити масштаб зображення, відредагувати зображення (наприклад, стерти непотрібні ділянки зображення, такі, як підписи чи великі ділянки сміття).
Додаток 3
Самостійна робота
Завдання 1.
Відсканувати текст і виконати його розпізнавання.
Для цього необхідно виконати таку послідовність дій:
1) відкрити кришку сканера, на скло покласти аркуш оригіналу зображенням донизу, закрити кришку;
2) запустити програму FineReader: START (ПУСК)\PROGRAMS (ПРОГРАМИ)\ABBYY FINEREADER 5.0\ABBYY FINEREADER PRO;
3) на панелі інструментів натиснути кнопку Scan (Сканувати), при цьому викличеться TWAIN-модуль сканера, в якому при необхідності можна встановити потрібні опції для зручного інтерфейсу. При цьому необхідно зважати на те, що у різних типів сканерів інтерфейс TWAIN-модуля різний;
4) при поверненні в інтерфейс FineReader, одержимо відскановане поки що графічне зображення, яке можна поділити на блоки вручну або це станеться атоматично, якщо відразу натиснути кнопку [Розпізнати];
5) при поділі на блоки вручно, кожен блок можна віднести до певного типу, в залежності від того, що в ньому знаходиться – звичайний текст, таблиця, картинка і т.п. Для цього достатньо у блоці клацнути правоюкнопкою миші і вибрати Тип (наприклад, Текст;
6) після цього натиснути кнопку [Розпізнати] для запуску програми розпізнавання символів;
7) після розпізнавання, можна виконати перевірку орфографії;
8) розпізнаний текстовий документ необхідно зберегти у форматі будь-якого текстового редактора, наприклад, Microsoft Word для подальшого його редагування: [ПЕРЕДАТИ В]\ПЕРЕДАТИ СТОРІНКУ В\MS WORD. Сканування таблиці з розпізнаванням виконується так, як сканування тексту, лише після поділу зображення на блоки, вибираємо тип блока “Таблиця”, а вже потім виконується розпізнавання.
Завдання 2.
Створити презентацію на тему « Сканери»
Додаток 3
Інструкція з техніки безпеки
Вимоги безпеки перед початком роботи
ЗАБОРОНЯЄТЬСЯ
- заходити в клас у верхньому одязі;
- приносити на робоче місце особисті речі;
- класти різні предмети або одяг на ПЕОМ і ін. обладнання;
- самостійно без вказівки майстра вмикати і вимикати пристрої;
- чіпати сполучні кабелі, від’єднувати і приєднувати роз'єми;
- дозволяється працювати тільки за вказівкою майстра в/н.
Вимоги безпеки під час роботи
ПІД ЧАС РОБОТИ ЗАБОРОНЯЄТЬСЯ:
- ходіння по класу без дозволу майстра;
- торкатися обладнання вологими руками;
- торкатися пальцями, авторучками і іншими предметами дисплея, а так само розеток електроживлення і роз'ємів пристроїв;
- залишати працююче місце устаткування без нагляду.
ПІД ЧАС РОБОТИ НЕОБХІДНО
- акуратно поводитися з апаратурою;
- працювати з клавіатурою чистими руками, на клавіші тиснути не сильно, не допускаючи ударів;
- у разі виникнення несправності повідомити майстру;
- не намагатися самостійно проводити регулювання або усувати несправності
апаратури.
Вимоги безпеки після закінчення роботи
ВИМОГИ БЕЗПЕКИ ПІСЛЯ ЗАКІНЧЕННЯ РОБОТИ
- Після закінчення роботи про недоліки і несправності, виявлені під час роботи,
необхідно зробити записи у відповідних журналах і повідомити майстра;
- Після закінчення, на робочому столі не повинні залишатися зайві предмети.


про публікацію авторської розробки
Додати розробку